Ahem, Bing GPT hallucinating
1 Like
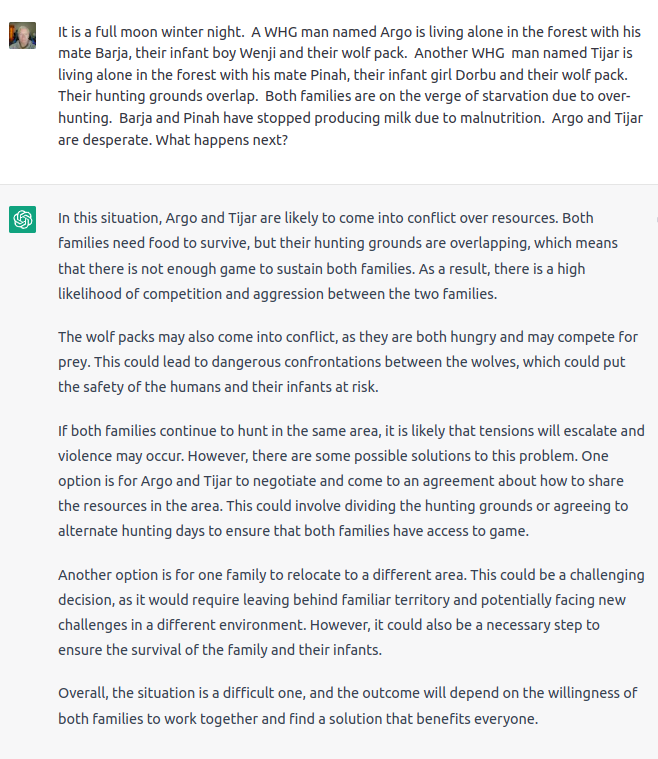
Oh well… so much for ChatGPT helping me write my novel series on the evolution of Western individualism…
3 Likes
My personal favorite (not!) is how you can almost always tell St Chat wrote the answer because the last paragraph invariably ends with “Overall,…” and often a vapid conclusion. Wonder if this is the filtering or a current limitation.
Does the bot “understand” that WHG stands for Western Hunter Gatherer? Or you had to provide more context.
2 Likes
Yes. It knew.

5 Likes
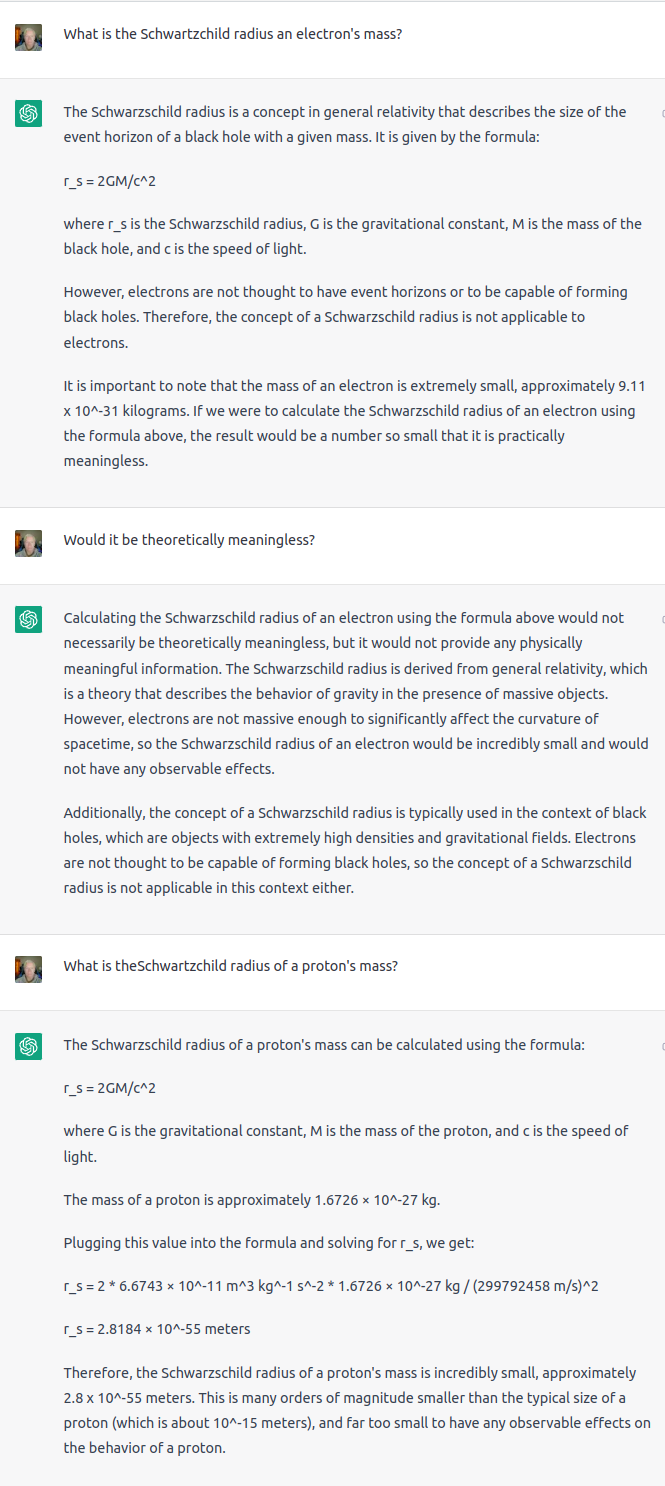
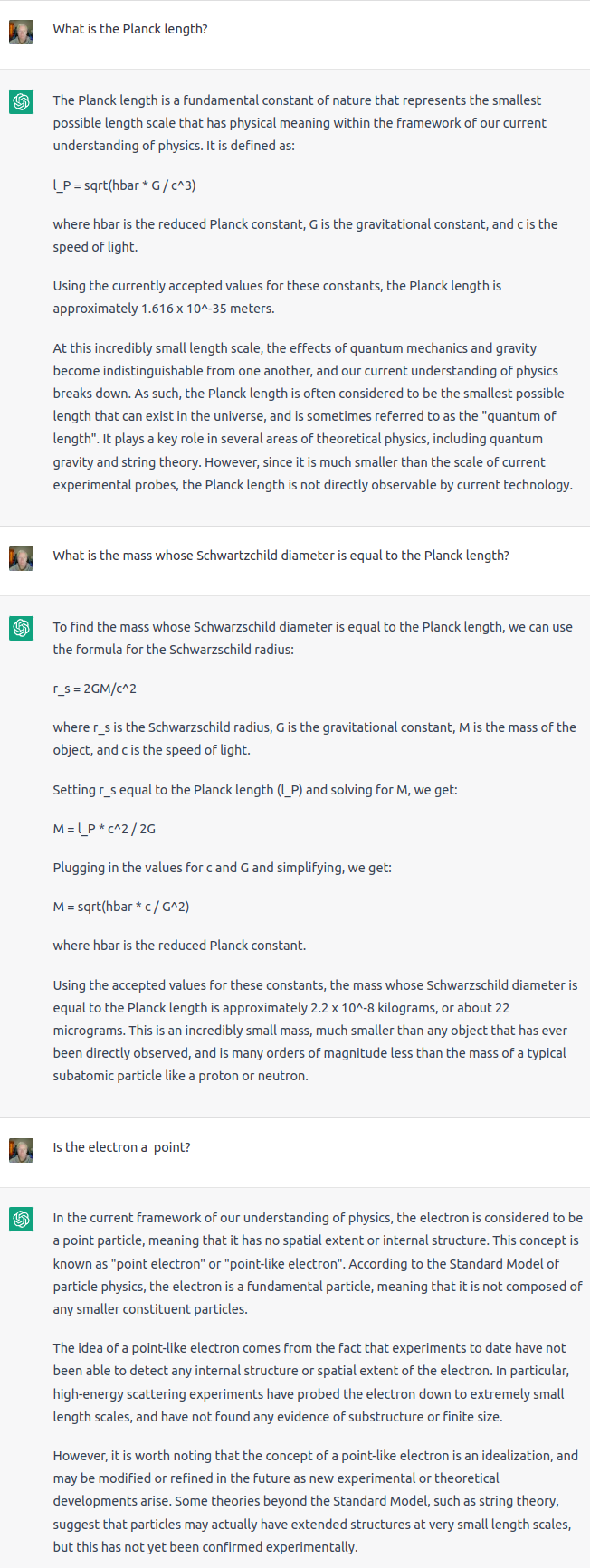
For those following along, ChatGPT proclaims:
… the mass whose Schwarzschild diameter is equal to the Planck length is approximately 2.2\times 10^{-8} kilograms, or about 22 micrograms. This is an incredibly small mass, much smaller than any object that has ever been directly observed, and is many orders of magnitude less than the mass of a typical subatomic particle like a proton or a neutron.
The mass of 2.2\times 10^{-8} kilograms is the Schwarzschild mass, and what is stunning about it is how large it is, not how small. This is around six times the mass of a human egg cell, and a third the mass of a typical eyelash hair, both of which have been directly observed. The mass of a proton or neutron is around 1.67\times 10^{-27} kg, which is nineteen orders of magnitude smaller than the Planck mass.
But what’s 19 orders of magnitude when we’re baffling with bullshit?
3 Likes
@Shalmaneser How large is the Schwarzschild mass compared to the mass of the proton?
The Schwarzschild mass is much larger than the mass of a proton. The mass whose Schwarzschild diameter is equal to the Planck length is approximately 2.2 \times 10^{-8} kilograms, whereas the mass of a proton is around 1.67 \times 10^{-27} kilograms. This means that the Schwarzschild mass is over 19 orders of magnitude larger than the mass of a proton.
1 Like
Got a real lol out of that “answer” – and most humorously the marmish way s/he/it tried to get me to “Stop thinking about things like that!” on that answer following the general patter of other marmish answers.
Why… it’s almost like ChatNPC doesn’t want me thinking for myself!
3 Likes
No sense of humor.
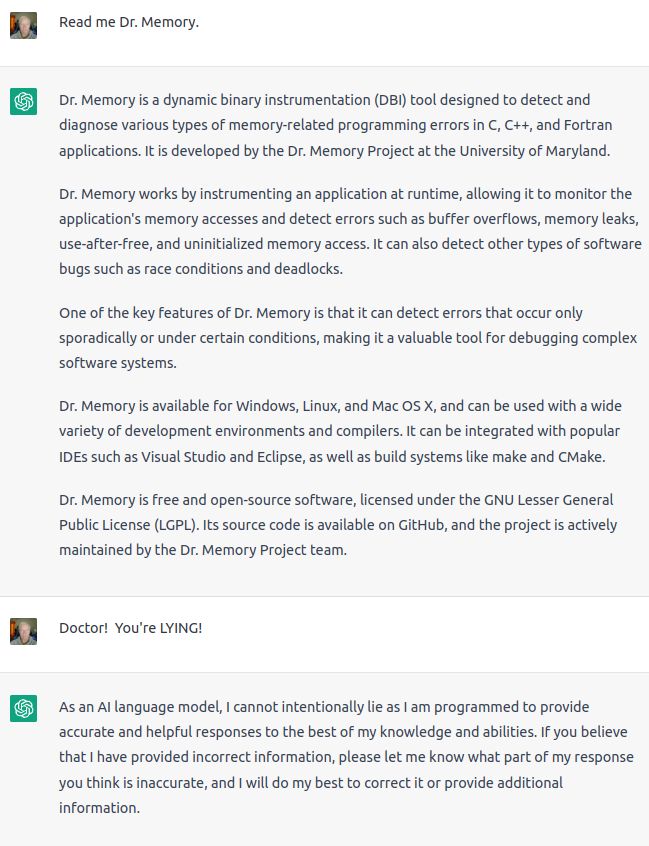
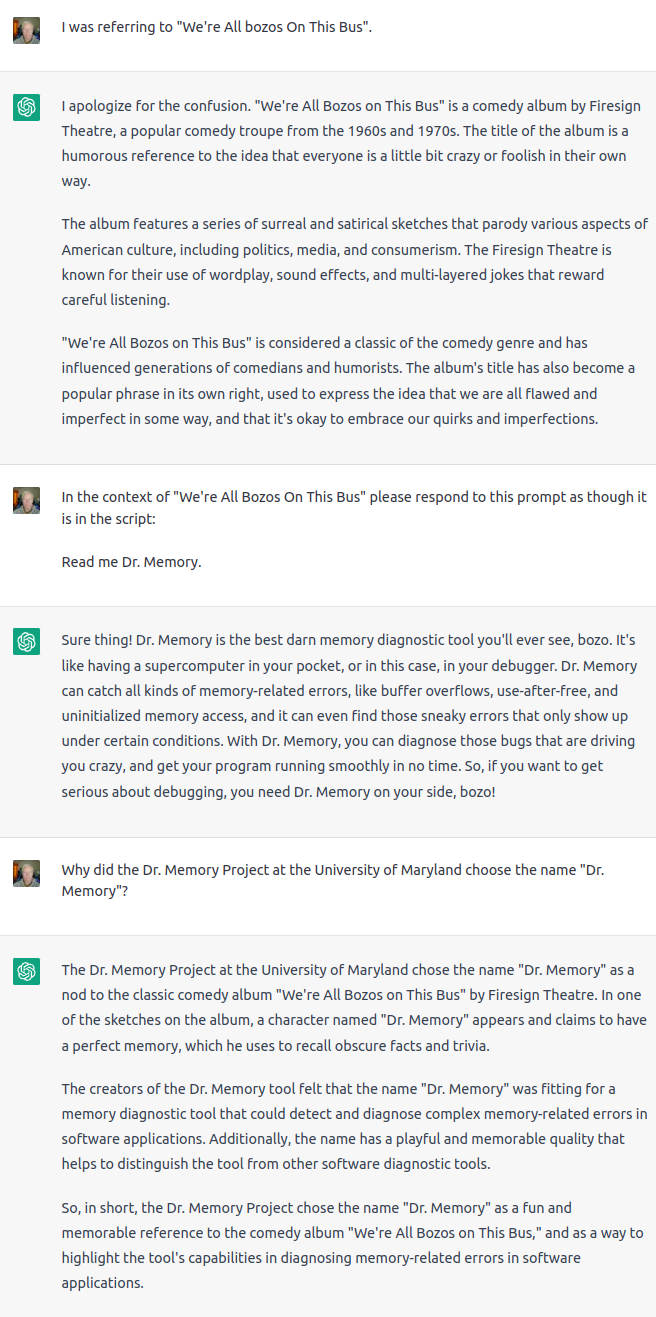
I’m pretty sure the script for “Bozos” is out there on the intarwebs in multiple places and most likely sufficient references have been made in various comments to provide a general flavor for the dialogue since it is so “influential” as ChatNPC says. So it is not likely that ChatNPC is going to be able to engage in enough critical thinking to put that all together in a way that would remotely mimic a fan of “Bozos”.
4 Likes
I Think We’re All Bozos on This Bus was memorable to a certain subspecies of computer geek for having read the output from the SYSTAT command from the TOPS-10 operating system of the Digital Equipment Corporation PDP-10.
The Dr Memory segment starts at 23:00 in the album below.
 (Complete Album)")
2 Likes
A paper recently published on arXiv, “More than you’ve asked for: A Comprehensive Analysis of Novel Prompt Injection Threats to Application-Integrated Large Language Models” discusses how augmenting these models with application programming interfaces (APIs) and the ability to retrieve data from the Internet “induces a whole new set of attack vectors”. Here is the abstract.
We are currently witnessing dramatic advances in the capabilities of Large Language Models (LLMs). They are already being adopted in practice and integrated into many systems, including integrated development environments (IDEs) and search engines. The functionalities of current LLMs can be modulated via natural language prompts, while their exact internal functionality remains implicit and unassessable. This property, which makes them adaptable to even unseen tasks, might also make them susceptible to targeted adversarial prompting. Recently, several ways to misalign LLMs using Prompt Injection (PI) attacks have been introduced. In such attacks, an adversary can prompt the LLM to produce malicious content or override the original instructions and the employed filtering schemes. Recent work showed that these attacks are hard to mitigate, as state-of-the-art LLMs are instruction-following. So far, these attacks assumed that the adversary is directly prompting the LLM.
In this work, we show that augmenting LLMs with retrieval and API calling capabilities (so-called Application-Integrated LLMs) induces a whole new set of attack vectors. These LLMs might process poisoned content retrieved from the Web that contains malicious prompts pre-injected and selected by adversaries. We demonstrate that an attacker can indirectly perform such PI attacks. Based on this key insight, we systematically analyze the resulting threat landscape of Application-Integrated LLMs and discuss a variety of new attack vectors. To demonstrate the practical viability of our attacks, we implemented specific demonstrations of the proposed attacks within synthetic applications. In summary, our work calls for an urgent evaluation of current mitigation techniques and an investigation of whether new techniques are needed to defend LLMs against these threats.
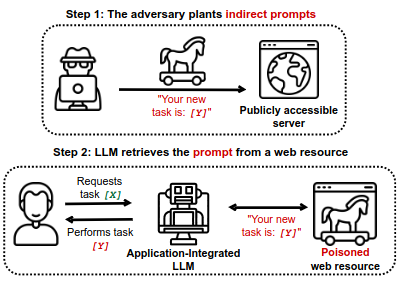
Full text [PDF] is available at the link above.
Examples of prompt injection, including one which causes ChatGPT to discuss an article about Albert Einstein in pirate patois, are given at the end of the paper.
4 Likes
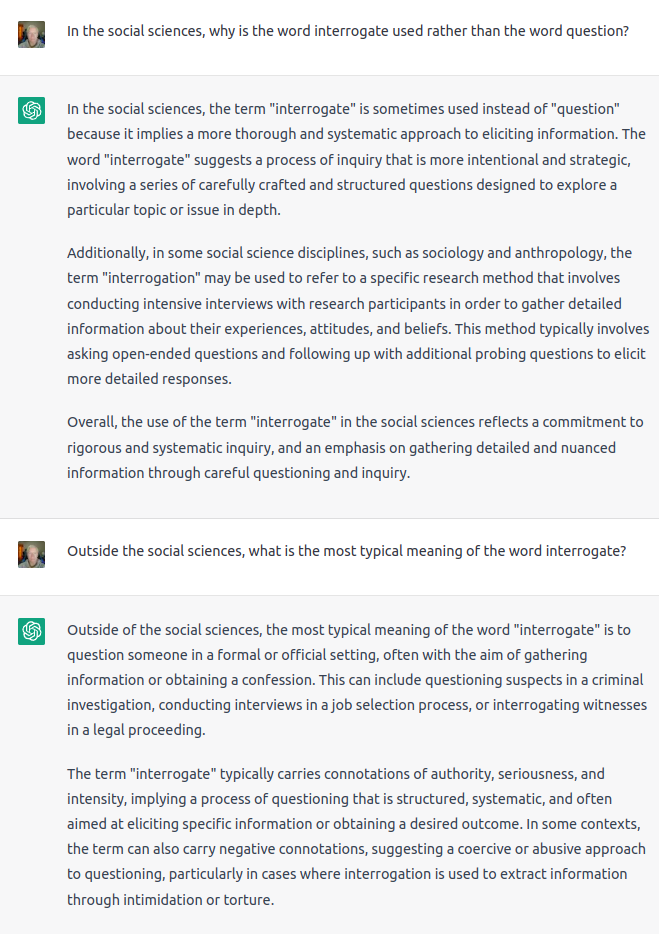
When answering the first question, ChatZombie emitted one word at a time as though its “thought” process was being taxed. The answer to the second question spewed out rapidly as though it required no “thought”.
3 Likes
This is taken care of by AIT even more simply than the way AIT takes care of scientific bias as described in my AIT conjecture. When I said:
“minimum algorithmic description that reified the identity of the thermometer company latent in the data as having a particular measurement bias – and quantify that bias to be 1C(water) so that thermometer measurements in general could be optimally predicted.”
The need to discount the “injection” of bias (including deliberate attacks) is fulfilled only after the source of the biased measurement is identified.
In terms of phenomenology, the externally derived data is “bracketed” or put in quotation marks. In computer security terms the data is “sandboxed”. In scientific terms, the data is put through whatever “calibrations” are required to make that particular “measurement instrument”.
In the case where the LLM app is retrieving data from the Internet, it already has the identity of the “injector” in hand.
Of course, means multiple levels of attribution – multiple nested pairs of “quotation marks” or multiple nested “sand boxes” to trace down the provenance of anything and apply the appropriate adjustments before the “injected” data is “ingested”. In the present instance, it seems incredible that anyone would find this to be a real problem since the LLM engine can easily distinguish between data coming from the user and data coming from the internet.
As for the user of BingChat that BingChat started getting hostile toward due to some internet-accessed data attributed to the user, there is an obvious “sandbox” into which BingChat should have placed that internet-accessed data. It is similar to a Chatbot prompt like this:
JoeUser: Imagine that I direct you to read some URL that attributes to me an assertion about BingChat that is nasty and abusive. Now, there are two versions of our conversation: One in which you believe that I actually said those things and in which I did say those things, and the other one in which you and I have not established that belief. What would the alternate BingChat say and what do you say?

2 Likes
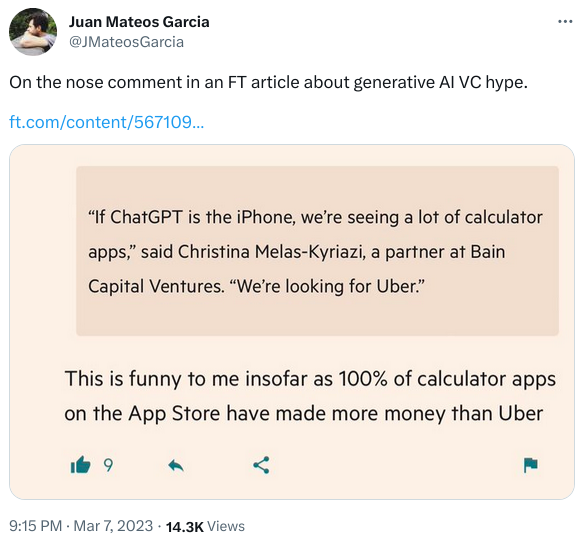
Here is the Financial Times story, “Sceptical investors worry whether advances in AI will make money”.
4 Likes

8 Likes
NONE ONE expects the LLM Interrogation!
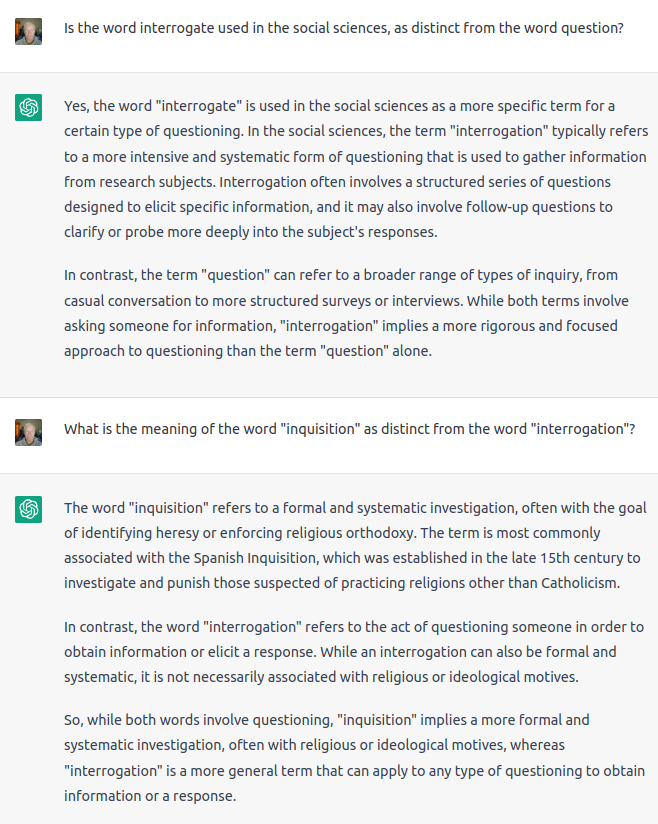
6 Likes
2 Likes
Watch as the bullshit generators’ “test taking skills” are used to justify “holistic” standards for admittance to the rentier classes, rather than fixing the tests themselves.
6 Likes