The “AI will be the end of civilization” theme is converging on clickbait - how do the promoters of this stand to make money though? Is it just through publicity, thus books, speeches, consulting? Flogging the fear of the unknown seems to be a lot of work though…
A hypothetical automated news architecture:
And a reminder about what’s at stake:
The most pressing threat to humanity in the years to come will come not from autonomous machines but from programmed people.
Though not recognized as such, extremely unreliable and flawed forms of these programmed devices, in the guise of human beings, have been around for thousands of years. Legions of soldiers marching unquestioningly to their deaths, religious cultists accepting articles of faith without doubt, individuals at the mercy of delusions and hallucinations . . . all, in retrospect, can be characterized at their most extreme moments, as behaving like what we now characterize as ‘robotic’.
4 Likes
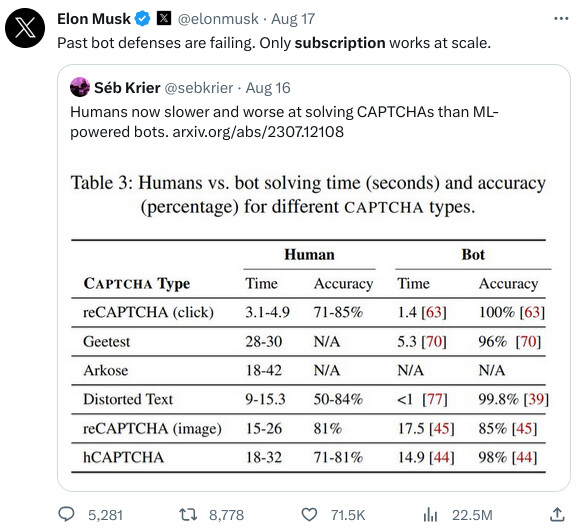
Here is the paper containing the quoted table, “An Empirical Study & Evaluation of Modern CAPTCHAs” (full text at link), the abstract follows.
For nearly two decades, CAPTCHAs have been widely used as a means of protection against bots. Throughout the years, as their use grew, techniques to defeat or bypass CAPTCHAs have continued to improve. Meanwhile, CAPTCHAs have also evolved in terms of sophistication and diversity, becoming increasingly difficult to solve for both bots (machines) and humans. Given this long-standing and still-ongoing arms race, it is critical to investigate how long it takes legitimate users to solve modern CAPTCHAs, and how they are perceived by those users.
In this work, we explore CAPTCHAs in the wild by evaluating users’ solving performance and perceptions of unmodified currently-deployed CAPTCHAs. We obtain this data through manual inspection of popular websites and user studies in which 1,400 participants collectively solved 14,000 CAPTCHAs. Results show significant differences between the most popular types of CAPTCHAs: surprisingly, solving time and user perception are not always correlated. We performed a comparative study to investigate the effect of experimental context — specifically the difference between solving CAPTCHAs directly versus solving them as part of a more natural task, such as account creation. Whilst there were several potential confounding factors, our results show that experimental context could have an impact on this task, and must be taken into account in future CAPTCHA studies. Finally, we investigate CAPTCHA-induced user task abandonment by analyzing participants who start and do not complete the task.
CAPTCHA is an overly-cute acronym which stands for “Completely Automated Public Turing test to tell Computers and Humans Apart“. Fourmilab’s Sentience Test, implemented as part of the Feedback Form, has been cited as an early example of a CAPTCHA, although it was not intended to distinguish humans from robots but rather sentient interlocutors from idiots, much like the “Bozo Filter” I invented on 1988-03-20 as an aid in choosing employees at Autodesk (it was never used).
Here’s a vintage CAPTCHA from the Winter War.
6 Likes
A majority of those polled want AI regulated by programmed people, i.e. government bureaucrats?
2 Likes
Every great civilization begins as a mutual property insurance company, establishes a reserve currency, is infected by rent seekers, shifts property insurance premiums to taxes on economic activity, eats its middle class and eventually liquidates its reserve currency to scatter well-funded spores infecting the world with even more highly evolved rent seekers.
10 Likes
This is pretty darn profound!! Kudos.
4 Likes
Thanks! You, @civilwestman, are on my short list of people whose opinions I value most highly regarding civilization.
2 Likes
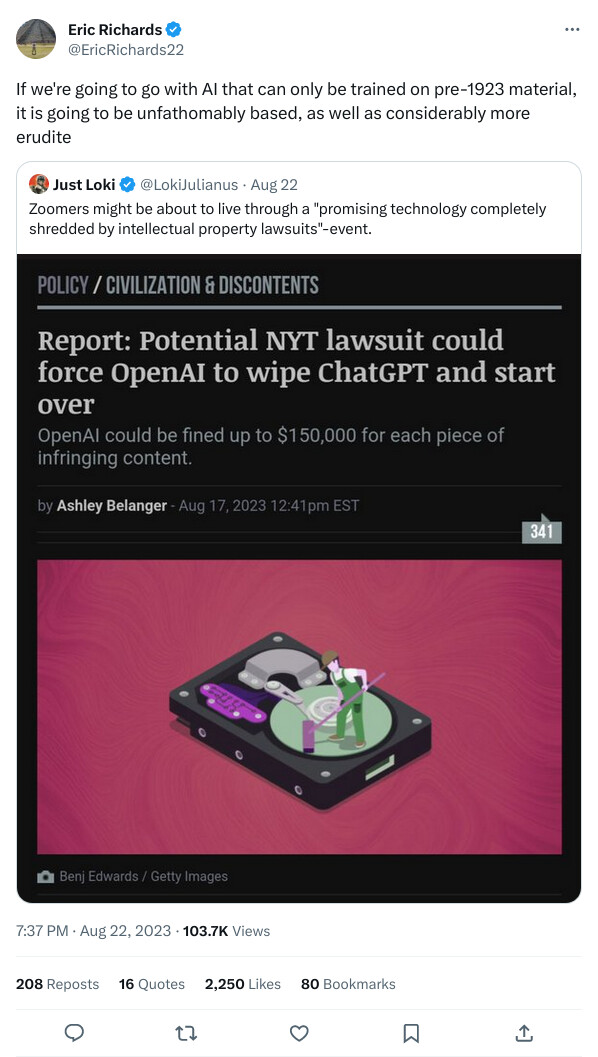
Weeks after The New York Times updated its terms of service (TOS) to prohibit AI companies from scraping its articles and images to train AI models, it appears that the Times may be preparing to sue OpenAI. The result, experts speculate, could be devastating to OpenAI, including the destruction of ChatGPT’s dataset and fines up to $150,000 per infringing piece of content.
NPR spoke to two people “with direct knowledge” who confirmed that the Times’ lawyers were mulling whether a lawsuit might be necessary “to protect the intellectual property rights” of the Times’ reporting.
Neither OpenAI nor the Times immediately responded to Ars’ request to comment.
If the Times were to follow through and sue ChatGPT-maker OpenAI, NPR suggested that the lawsuit could become “the most high-profile” legal battle yet over copyright protection since ChatGPT’s explosively popular launch. This speculation comes a month after Sarah Silverman joined other popular authors suing OpenAI over similar concerns, seeking to protect the copyright of their books.
Of course, ChatGPT isn’t the only generative AI tool drawing legal challenges over copyright claims. In April, experts told Ars that image-generator Stable Diffusion could be a “legal earthquake” due to copyright concerns.
But OpenAI seems to be a prime target for early lawsuits, and NPR reported that OpenAI risks a federal judge ordering ChatGPT’s entire data set to be completely rebuilt—if the Times successfully proves the company copied its content illegally and the court restricts OpenAI training models to only include explicitly authorized data. OpenAI could face huge fines for each piece of infringing content, dealing OpenAI a massive financial blow just months after The Washington Post reported that ChatGPT has begun shedding users, “shaking faith in AI revolution.” Beyond that, a legal victory could trigger an avalanche of similar claims from other rights holders.
5 Likes
Here’s a dramatization of a related quote
 - Top Dollar monologue.avi")
3 Likes
7 Likes
Just published on arXiv, 2023-09-19, “Language Modeling Is Compression”(full text at link). Here is the abstract:
It has long been established that predictive models can be transformed into lossless compressors and vice versa. Incidentally, in recent years, the machine learning community has focused on training increasingly large and powerful self-supervised (language) models. Since these large language models exhibit impressive predictive capabilities, they are well-positioned to be strong compressors. In this work, we advocate for viewing the prediction problem through the lens of compression and evaluate the compression capabilities of large (foundation) models. We show that large language models are powerful general-purpose predictors and that the compression viewpoint provides novel insights into scaling laws, tokenization, and in-context learning. For example, Chinchilla 70B, while trained primarily on text, compresses ImageNet patches to 43.4% and LibriSpeech samples to 16.4% of their raw size, beating domain-specific compressors like PNG (58.5%) or FLAC (30.3%), respectively. Finally, we show that the prediction-compression equivalence allows us to use any compressor (like gzip) to build a conditional generative model.
Eleven of the twelve authors (including Marcus Hutter) are with Google DeepMind, while one is from Meta AI and Inria. The Hutter Prize is cited in the References.
7 Likes
Recently published at arXiv on 2023-09-13, “Auto-Regressive Next-Token Predictors are Universal Learners” (full text at link). Here is the abstract:
Large language models display remarkable capabilities in logical and mathematical reasoning, allowing them to solve complex tasks. Interestingly, these abilities emerge in networks trained on the simple task of next-token prediction. In this work, we present a theoretical framework for studying auto-regressive next-token predictors. We demonstrate that even simple models such as linear next-token predictors, trained on Chain-of-Thought (CoT) data, can approximate any function efficiently computed by a Turing machine. We introduce a new complexity measure – length complexity – which measures the number of intermediate tokens in a CoT sequence required to approximate some target function, and analyze the interplay between length complexity and other notions of complexity. Finally, we show experimentally that simple next-token predictors, such as linear networks and shallow Multi-Layer Perceptrons (MLPs), display non-trivial performance on text generation and arithmetic tasks. Our results demonstrate that the power of language models can be attributed, to a great extent, to the auto-regressive next-token training scheme, and not necessarily to a particular choice of architecture.
Among the experiments they discuss is training a simple model to perform multiplication of four digit numbers:
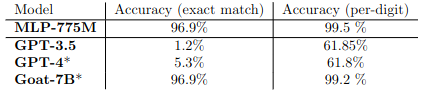
We focus on the task of multiplying two 4-digit numbers, which has been shown to be challenging even for huge language models such as GPT-4. For this task, we train a simple Multi-Layered Perceptron (MLP) with four layers: 1) a standard (linear) embedding layer, from tokens to dimension d = 128; 2) a linear layer with a ReLU activation, applied across all the context window, mapping the input of d × T to an output of d × T (where we use a context length of T = 307); 3) a linear layer with a ReLU activation applied per token, mapping from d to d; 4) a final output embedding, mapping back to the space of all tokens (see Figure 1 for illustration of the architecture). Similarly to the linear network, we mask future positions in the second layer. We note that while this network is non-linear (unlike the models discussed previously), it is still very simple, and very far from standard transformer-based networks (e.g., we use no attention mechanism). Altogether, our MLP has 775M active parameters.
⋮
We split all pairs of 4-digit numbers arbitrarily, use 75% for training, and keep the rest for validation. The network is trained from scratch for 17 hours on a single A100 GPU, going over 100M sequences (307M tokens) sampled uniformly from the training set. In Table 1 we compare the performance of our simple MLP (evaluated on 1000 validation examples) with GPT-3.5 (evaluated on the same examples), as well as to GPT-4 and Goat-7B on the same task.
3 Likes
2 Likes
Defense Distributed is developing “GatGPT - Liberated Gun AI”.
From the FAQ page:
What is GatGPT?
GatGPT is an experimental LLM-based agent developed by Defense Distributed and trained on both open source and proprietary firearms files, texts, and datasets.Who can use GatGPT?
GatGPT is built for public and business users. In our private beta, invited users will also act as beta testers to improve the model’s responses.What is the role of a GatGPT beta tester?
Beta testers give feedback on the model’s responses and some testers will serve in a data auditing capacity. Beta testers are our partners in developing the Internet’s best, unbiased public resource for firearms information.What does GatGPT cost to use?
Private beta testers are asked to pay a $5 upfront fee to indicate interest and dedication to helping test the model. Upon public launch, a monthly subscription model is anticipated for general access.Why have you built GatGPT?
GatGPT was built by expert engineers, scholars and activists from datasets disputed by private and government agencies, in service of the rights and interests of the American rifleman. See our Digital Second Amendment.How can I learn more?
Join our waitlist here to become a beta tester or business user. Questions? Email us at: crw@defcad.com
2 Likes
3 Likes
New Chinese model from Alibaba:
New French model from MistralAI:
magnet:?xt=urn:btih:208b101a0f51514ecf285885a8b0f6fb1a1e4d7d&dn=mistral-7B-v0.1&tr=udp%3A%2F%[http://2Ftracker.opentrackr.org](https://t.co/OdtBUsbMKD)%3A1337%2Fannounce&tr=https%3A%2F%[http://2Ftracker1.520.jp](https://t.co/HAadNvH1t0)%3A443%2Fannounce
3 Likes
3 Likes
So Zuck’s going to be upgrading his human emulator core then…
3 Likes
You can try Mistral here https://labs.perplexity.ai/
Apparently it’s quite uncensored, throwing culture warriors into hysteric fits.
2 Likes