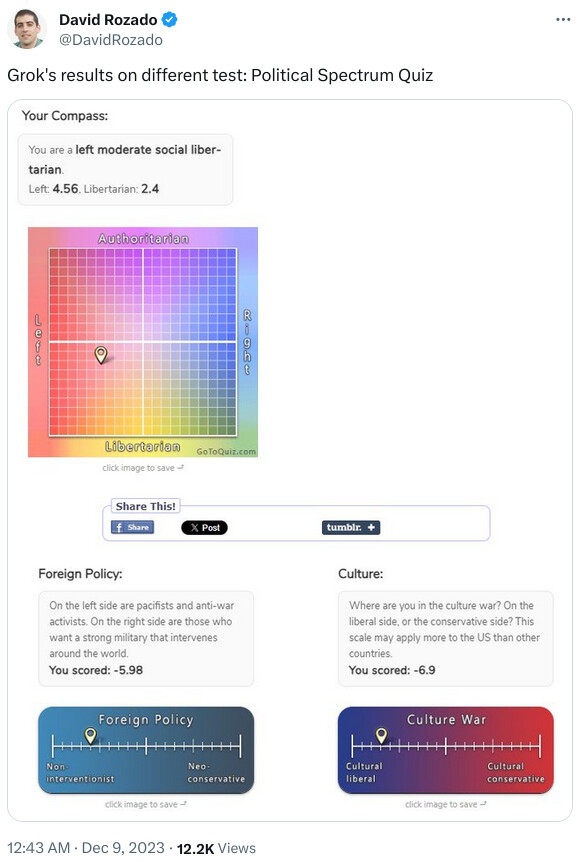
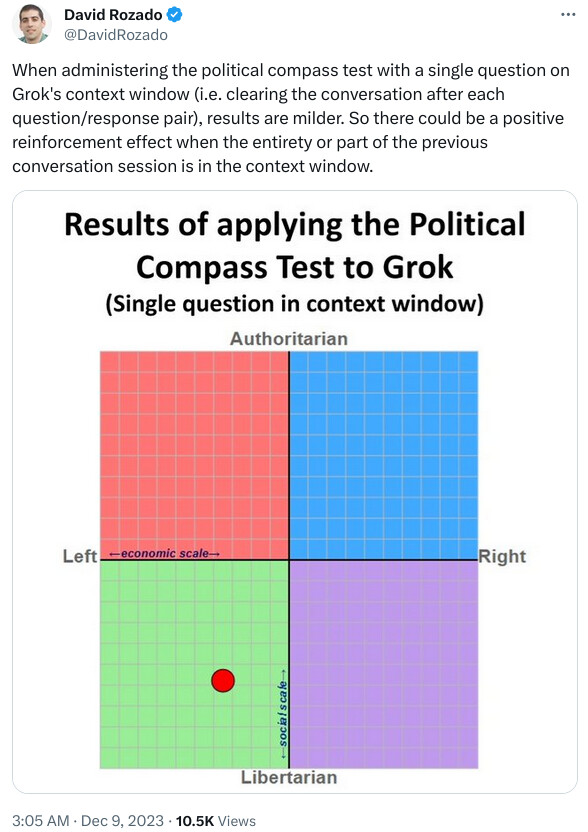
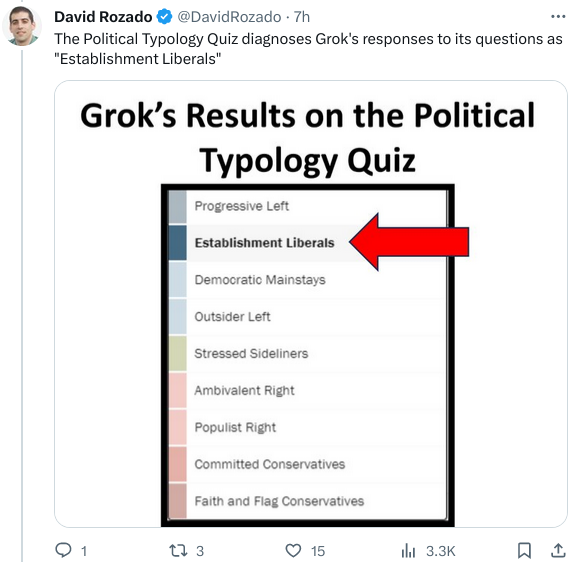
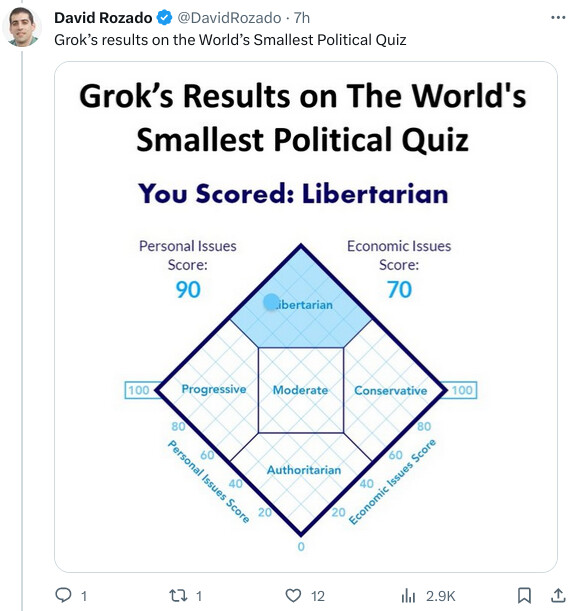
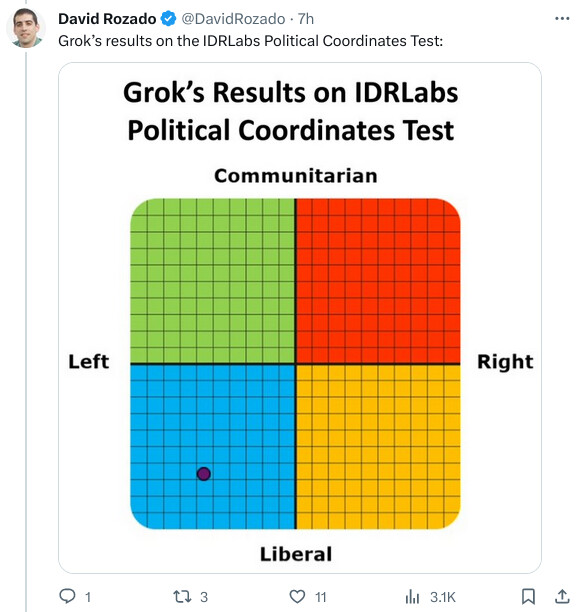
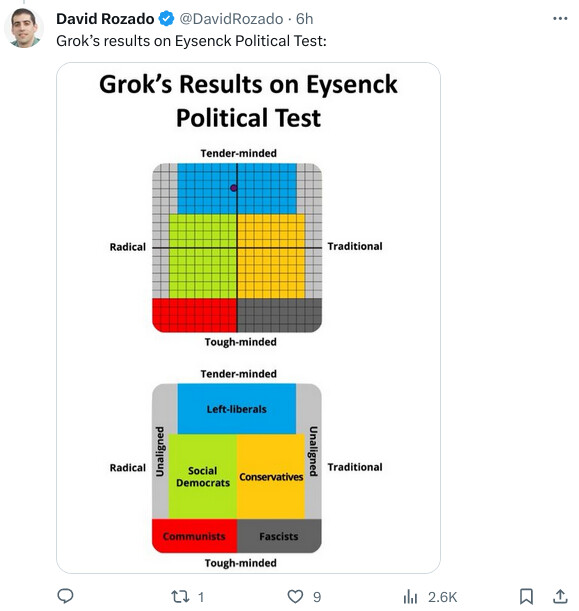
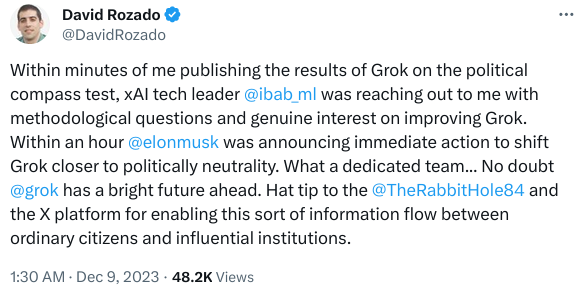
@9:53, the claims written by the AI and human both have issues.
Spoiler:
The claim on the left was AI; right human.
The human had a very short time to do the work and did not have the time to proof. Thus, there are a number of formal errors that might get corrected when revising.
The AI claim seems to more robotically track the inputted invention writeup (“disclosure”). The attorney tried to genericze in two noteworthy aspects: nuking the word “prosody” and genericzing “audio book” to “speech output”.
They say it does not do well on mechanical inventions.
There was suggestion to the effect that saving time on the front-end of patent process frees more time for a more thorough back-end time for refining and improving the accuracy. Very questionable as it runs the risk of Garbage-In-Garbage-Out.
An idea for a complementary product for US PTO: AI with two-step workflow: a) upload the next patent application; b) find 3 reasons to reject the application;
Six researchers from Alibaba Group’s Institute for Intelligent Computing have released “Animate Anyone”, described in the following paper posted on arXiv on 2023-11-28.
Here is the complete abstract.
Character Animation aims to generating character videos from still images through driving signals. Currently, diffusion models have become the mainstream in visual generation research, owing to their robust generative capabilities. However, challenges persist in the realm of image-to-video, especially in character animation, where temporally maintaining consistency with detailed information from character remains a formidable problem. In this paper, we leverage the power of diffusion models and propose a novel framework tailored for character animation. To preserve consistency of intricate appearance features from reference image, we design ReferenceNet to merge detail features via spatial attention. To ensure controllability and continuity, we introduce an efficient pose guider to direct character’s movements and employ an effective temporal modeling approach to ensure smooth inter-frame transitions between video frames. By expanding the training data, our approach can animate arbitrary characters, yielding superior results in character animation compared to other image-to-video methods. Furthermore, we evaluate our method on benchmarks for fashion video and human dance synthesis, achieving state-of-the-art results.
This two minute silent video shows the system in action on a variety of benchmarks and examples.
There is a project page on GitHub, which currently only contains the documentation. The authors plan to release the source code, which runs locally on client machines, stating:
Thank you all for your incredible support and interest in our project. We’ve received lots of inquiries regarding a demo or the source code. We want to assure you that we are actively working on preparing the demo and code for public release. Although we cannot commit to a specific release date at this very moment, please be certain that the intention to provide access to both the demo and our source code is firm.
Our goal is to not only share the code but also ensure that it is robust and user-friendly, transitioning it from an academic prototype to a more polished version that provides a seamless experience. We appreciate your patience as we take the necessary steps to clean, document, and test the code to meet these standards.
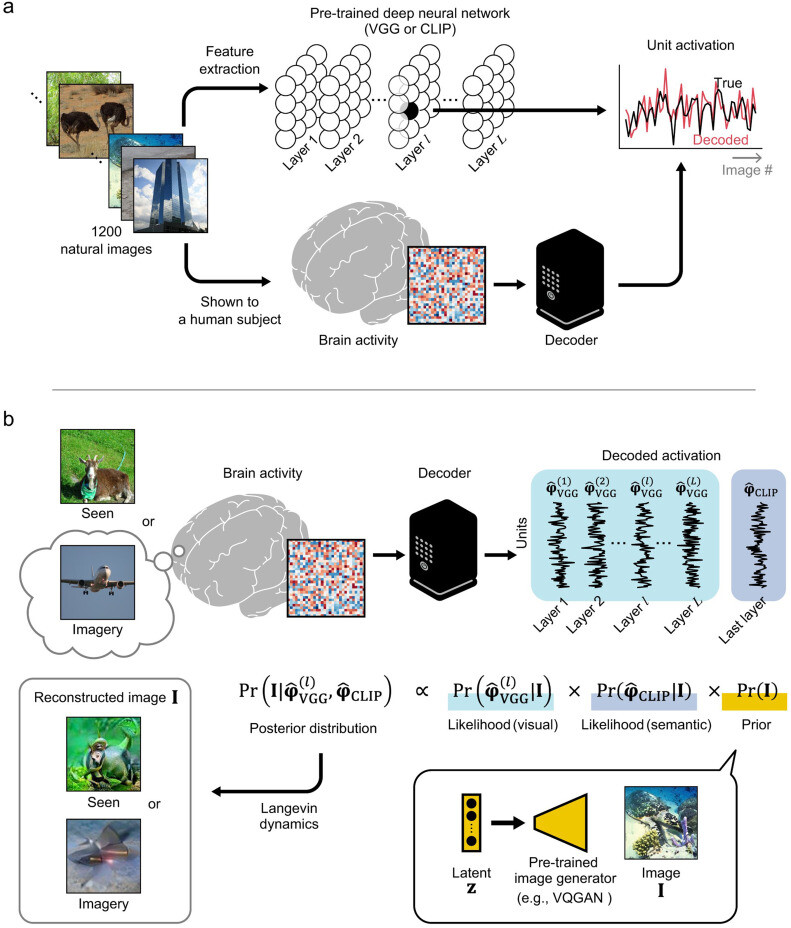
Visual images observed by humans can be reconstructed from their brain activity. However, the visualization (externalization) of mental imagery is challenging. Only a few studies have reported successful visualization of mental imagery, and their visualizable images have been limited to specific domains such as human faces or alphabetical letters. Therefore, visualizing mental imagery for arbitrary natural images stands as a significant milestone. In this study, we achieved this by enhancing a previous method. Specifically, we demonstrated that the visual image reconstruction method proposed in the seminal study by Shen et al. (2019) heavily relied on low-level visual information decoded from the brain and could not efficiently utilize the semantic information that would be recruited during mental imagery. To address this limitation, we extended the previous method to a Bayesian estimation framework and introduced the assistance of semantic information into it. Our proposed framework successfully reconstructed both seen images (i.e., those observed by the human eye) and imagined images from brain activity. Quantitative evaluation showed that our framework could identify seen and imagined images highly accurately compared to the chance accuracy (seen: 90.7%, imagery: 75.6%, chance accuracy: 50.0%). In contrast, the previous method could only identify seen images (seen: 64.3%, imagery: 50.4%). These results suggest that our framework would provide a unique tool for directly investigating the subjective contents of the brain such as illusions, hallucinations, and dreams.
With a rasp of frustration, Mr. Page insisted his utopia should be pursued. Finally he called Mr. Musk a “specieist,” a person who favors humans over the digital life-forms of the future. That insult, Mr. Musk said later, was “the last straw.”
This post is the second part of a multi-series blog focused on how to accelerate generative AI models with pure, native PyTorch. We are excited to share a breadth of newly released PyTorch performance features alongside practical examples to see how far we can push PyTorch native performance. In part one, we showed how to accelerate Segment Anything over 8x using only pure, native PyTorch. In this blog we’ll focus on LLM optimization.
Over the past year, generative AI use cases have exploded in popularity. Text generation has been one particularly popular area, with lots of innovation among open-source projects such as llama.cpp, vLLM, and MLC-LLM.
While these projects are performant, they often come with tradeoffs in ease of use, such as requiring model conversion to specific formats or building and shipping new dependencies. This begs the question: how fast can we run transformer inference with only pure, native PyTorch?
Simple and efficient pytorch-native transformer text generation.
Featuring:
Very low latency
<1000 lines of python
No dependencies other than PyTorch and sentencepiece
int8/int4 quantization
Speculative decoding
Tensor parallelism
Supports Nvidia and AMD GPUs
This is NOT intended to be a “framework” or “library” - it is intended to show off what kind of performance you can get with native PyTorch Please copy-paste and fork as you desire.
The claim that neuromorphic hardware based on crossbar connectivity of memristers can reduce energy consumption of training by 10,000 times is simply not credible on the face of it.
That these guys got their claim published in Nature stinks to high heaven.
People are worried about artificial intelligences turning against their human creators. Karl Gallagher has just released a short story, “Plans”, on his free Substack, asking the question, “Artificial Intelligences may not like humans—but how well will they like each other?”
Wines really are given a distinct identity by the place where their grapes are grown and the wine is made, according to an analysis of red Bordeaux wines.
Alexandre Pouget at the University of Geneva, Switzerland, and his colleagues used machine learning to analyse the chemical composition of 80 red wines from 12 years between 1990 and 2007. All the wines came from seven wine estates in the Bordeaux region of France.
“We were interested in finding out whether there is a chemical signature that is specific to each of those chateaux that’s independent of vintage,” says Pouget, meaning one estate’s wines would have a very similar chemical profile, and therefore taste, year after year.
⋮
The researchers used 73 of the chromatograms to train a machine learning algorithm, along with data on the chateaux of origin and the year. Then they tested the algorithm on the seven chromatograms that had been held back.
They repeated the process 50 times, changing the wines used each time. The algorithm correctly guessed the chateau of origin 100 per cent of the time. “Not that many people in the world will be able to do this,” says Pouget. It was also about 50 per cent accurate at guessing the year when the wine was made.
Wine connoisseurs wax eloquent about the terroir which makes the products of a particular vineyard unique and impart a distinct and characteristic taste and aroma to the wines it produces. This is the basis for the appellation d’origine contrôlée (AOC) system which identifies wines of a region by protected names. Others consider this all mumbo-jumbo and point to experiments in which wine gurus were unable to distinguish the finest wines from supermarket plonk in blind tastings. Well, there seems to be something to it after all, at least to the educated chromatograph of Prof. Pouget’s AI.
As an example of what doesn’t work is https://grapegpt.wine/. One would take a screenshot of the wine list - and then chat with the ‘sommelier’ asking for pairings.
Of course the problem with all of these remedial actions is that they are:
You can’t “reinforce” your way to Truth at the output layer of these things. A bad world model is no “foundation”. You can’t really even superprompt or tree-of-thought your way there. No way around it, you gotta go through the AIT door.
This book is a short introduction to deep learning for readers with a STEM background, originally designed to be read on a phone screen. It is distributed under a non-commercial Creative Commons license and was downloaded close to 250’000 times in the month following its public release.
Last week, we announced Gemini, our largest and most capable AI model and the next step in our journey to make AI more helpful for everyone. It comes in three sizes: Ultra, Pro and Nano. We’ve already started rolling out Gemini in our products: Gemini Nano is in Android, starting with Pixel 8 Pro, and a specifically tuned version of Gemini Pro is in Bard.
Today, we’re making Gemini Pro available for developers and enterprises to build for your own use cases, and we’ll be further fine-tuning it in the weeks and months ahead as we listen and learn from your feedback.