4 Likes









Typically, Yudowsky misses the point of general intelligence:
The features being predicted by these statistical models are statistical and have little to do with the algorithmic or dynamical models required to make predictions about the real world. Sure, they are superhuman at identifying these kinds of patterns but if you, for instance, stack them up against a human in, say, taking a Wikipedia article on “race” and making predictions about the kinds of arguments that are going to be permitted to appear, the human is going to be far better because the human has latent variable models like the bias of the editors of Wikipedia.
And people don’t understand why I was so adamant about using Wikipedia as the corpus for the Hutter Prize – the only AI competition out there that forces participants into the use of Algorithmic Information rather than mere statistics.
That was over 15 years ago and people still don’t get it – even though ChatGPT is now making it obvious that the bullshitters are closing in for the kill by keeping everyone in the dark about why the social sciences have been bullshitting people for decades about causal inference by ignoring algorithmic information.
Time is running short, folks.
I’m not sure what is the best way of battering through this barrier to squeezing out bias from these models with lossless compression but people who give a rats ass about civilization had better get on it.
4 Likes
If I get the gist of this thread (and I’m not sure I do), this assertion that arithmetic is racist and oppressive, was generated by chatGPT in response to a prompt. We already hear excuses that censorship is “merely” due to some “objective” algorithm. Again, I am not sure I understand this thread -and would be glad for any enlightenment - but it seems to me an algorithm may be constructed to give any result desired by its creator. Not so?
As to the monologue - “the way in which arithmetic is used to deny and suppress my truth” - It is beyond ironic that the same kind of people who actually make such arguments are the first to label what they disagree with as “mis” or “dis” - “information.” If arithmetic is not objective and independent of the user, how on earth can any fact be labeled as correct as opposed to “misinformation”?
4 Likes
Assuming all of the inputs are precisely specified and there is no stochastic input to the algorithm (which isn’t always the case—some algorithms, such as simulated annealing, often used in optimisation problems, depend upon a degree of randomness to avoid getting stuck in local maxima when seeking a solution), the output will always be the same.
But these large language models are doing something different than a normal algorithm. What they’re trying to do (vastly oversimplified) is predict, from a prompt and the weights computed from the training set from which they were built, what is the most probable completion according to the corpus of text they have seen. This is done using low precision computation and probably some randomness, so it does not produce the same result every time.
This is a very different process than the kind of “algorithm” social media companies speak of when they talk about filtering for content they wish to suppress. They may be using the same kind of fundamental technique (a large neural network used to match patterns against a set upon which it has been trained), but the result is not a prediction of continuation but rather a thumb up or down based upon whether the content being tested appears similar to something the network was trained to reject.
Here, the details of how the network is implemented are less important than the contents of the training set. If there is a bias in the training set, the algorithm will faithfully embody that bias. In comment #37 and subsequently I discussed David Rozado’s experiments testing ChatGPT with various political alignment tests, which led him to conclude its “Establishment Liberal” identification was likely due to a large amount of such material in its training set.
5 Likes
The censors claim they are suppressing damage from falsehoods:
- Objectively false facts or
- Subjectively false facts, ie: truths that require “contextualization” to portray the objective truth.
The unspoken assumption behind both of these forms of censorship is that the censors are in possession of the objective truth at least to the degree required to pass judgement on the speech being censored. In the case of “contextualization” they must also possess some objective truth about the person potentially reading a fact in order to know that person needs to be provided said context. This amounts to something like “placement” in computer-based education where a student’s knowledge is modeled by the educating algorithm in order to know what prerequisites the student needs to not misunderstand some fact like E=mc^2.
These are ultimately objective truths provided by the natural sciences including the social sciences:
What “is” the case.
Let’s set aside, for the moment, the question of what constitutes “damage” as that goes beyond objective truth to “ought”, and stick with objective truth, ie: natural science.
The network effect monopolies are in possession of oceans of not only data (their own plus all published data) but also mountains of cash and clouds of computers for turning all that data into one big unified model of what “is”. If they did so, they might be in a position to pass judgement on objective truths, hence what might be damaging falsehoods.
When I speak of “Algorithmic Information” I’m speaking of an ideal that can only be approximated:
All of the available data transformed into the smallest possible algorithm aka program.
Quoting Minsky’s final advice:

“The most important discovery since Godel is Algorithmic Probability which is a fundamental new theory of how to make predictions given a collection of experiences… This is a beautiful theory… that will make better predictions than anything we have today and everybody should learn all about that and spend the rest of their lives working on it.”
“Algorithmic Probability” is a subdiscipline of Algorithmic Information. It is about what is the case about probability distributions of what will be the case: The natural sciences.
So, we must distinguish between whatever “algorithms” the censors are using to censor and the Algorithmic Information that is the embodiment of the best model of reality given all the available data.
ChatGPT and other large language models have as their “available data” a huge portion of the data available on the network. They have even “compressed” that data but have done so in a manner that throws away vast amounts of data keeping only “relevant” data. But any attempt to decide to discard some data from one’s model must penalize the model in some manner otherwise we’ll be potentially committing Ockham’s Chainsaw Massacre and – in particular – be subject to “confirmation bias” by cherry picking data. This is, in fact, what all of the social sciences do by avoiding, as their output, a unified macrosocial model that use Algorithmic Information Criterion (degree of lossless compression) to decide what “is” the case about society. It is also what the Large Language Models have industrialized by using the same statistical information criteria as the social sciences.
Now, why oh why in the world would the woke corporations want to use the same biased model selection criteria for their “unbiased” models (like ChatGPT) as the social sciences have been using as they’ve taken wrecking ball to Western Civilization for over half a century?
I’ve heard all the excuses for over 15 years and I’m convinced the answer is the same as it was when theocrats resisted the scientific method during The Enlightenment.
5 Likes
Mother of babbling…. ChatGPT does geometrical optics ray tracing. This is the first prompt I tried and first reply I got, and it’s completely correct.

5 Likes
So, as I would suspect, when it comes to physical sciences, where objective truth can actually be determined, these programs are trustworthy. As I read comment 37, then, when it comes to psychology and social “sciences” (whose written materials are filled with received wisdom and opinion/utopian wishing masquerading as “science”) the training set results in a liberal bias. Thus, in fact, the choice of the training materials is determinative of the output. I am moved to agree with @jabowery ‘s cautions.
4 Likes






If there were a real science of “Algorithmic Bias” – one that studies the degree to which optimal Algorithmic Information models can be biased by their training data, rather than a technology that serves the opposite purpose (as a theocratic watchdog in imposing its moral bias via kludges) – it would study error propagation with an eye toward interdisciplinary consilience. But before talking about that, we can see that even intradisciplinary bias in the data needs to be quantified.
For example let’s say there is a body of work that keeps reporting the boiling point of water is 99C and another body of work that keeps reporting 100C. The Algorithmic Information of these observations might add 1C to the former or subtract 1C from the later (both subtraction and addition increasing the number of algorithmic bits by the same amount in the resulting algorithmic information). The balance tips, however, when considering the number of “replications”. The choice of which of these two complications may seem arbitrary, but it does get into a kind of “voting” except it’s logarithmic base 2 of the number of replications:
If there are 2^12 reports of 99C and only 2^9 reports of 100C then it makes sense to declare the 100C reports as “biased” because it takes fewer bits to count the number of times the bias-correction must be applied.
Now, obviously, there may be other observations, such as barometric pressure, that may be brought to bear in deciding which body of measurements of the boiling point should be treated as “biased”. So, for example, if it is quite common for measurements of other physical quantities to be taken at sea-level where standard pressure is common, then consilience with those other measurements may amortize the extra bits it takes to treat 100C as the “true” boiling point of water.
When we get into more extreme cases of cross-disciplinary consilience, such as we would see between physics and chemistry, the case counting and log2 “voting” becomes more sophisticated but, in effect, increases the confidence in some “truths” by increasing their votes from other disciplines.
If you get into consilience between, say, the Genome Wide Association Study and various models of social causation derived from, say, public government data sources, the cross-disciplinary consilience cross-checks become even more sophisticated.
If we get into language models, where all of this knowledge is being reduced to speech that supposedly conveys scientific observations latent in their assertions, it gets even more sophisticated.
But the principle remains the same.
This is why I saw Wikipedia’s ostensible wide-range of human knowledge, as a target-rich environment for exposing the more virulent forms of bias that are threatening to kill us all.
I am unspeakably sad for humanity the Hutter Prize has not received more monetary support since it is a very low risk investment for very high returns for the future of humanity, and in the intervening 17 years the enemies of humanity have made enormous strides in industrializing “Algorithmic Bias” to the point that we may soon see very persuasive computer based education locking us into what John Robb has called “The Long Night”.
5 Likes

Edit: I gave GPT-3 some more words to finish the story and ran it a few times. It usually ended with “and everyone lived happily ever after under the rule of the woke technocrats”, but there were occasional glimmers of rebellion. Here are a few alternate endings.
“…a shining example of what can be achieved when the right people are in charge.”

“…the United States will remain a nation ruled by woke technocrats for the foreseeable future.”

“The people had traded freedom for security, and in the end, it seemed like a fair trade.”
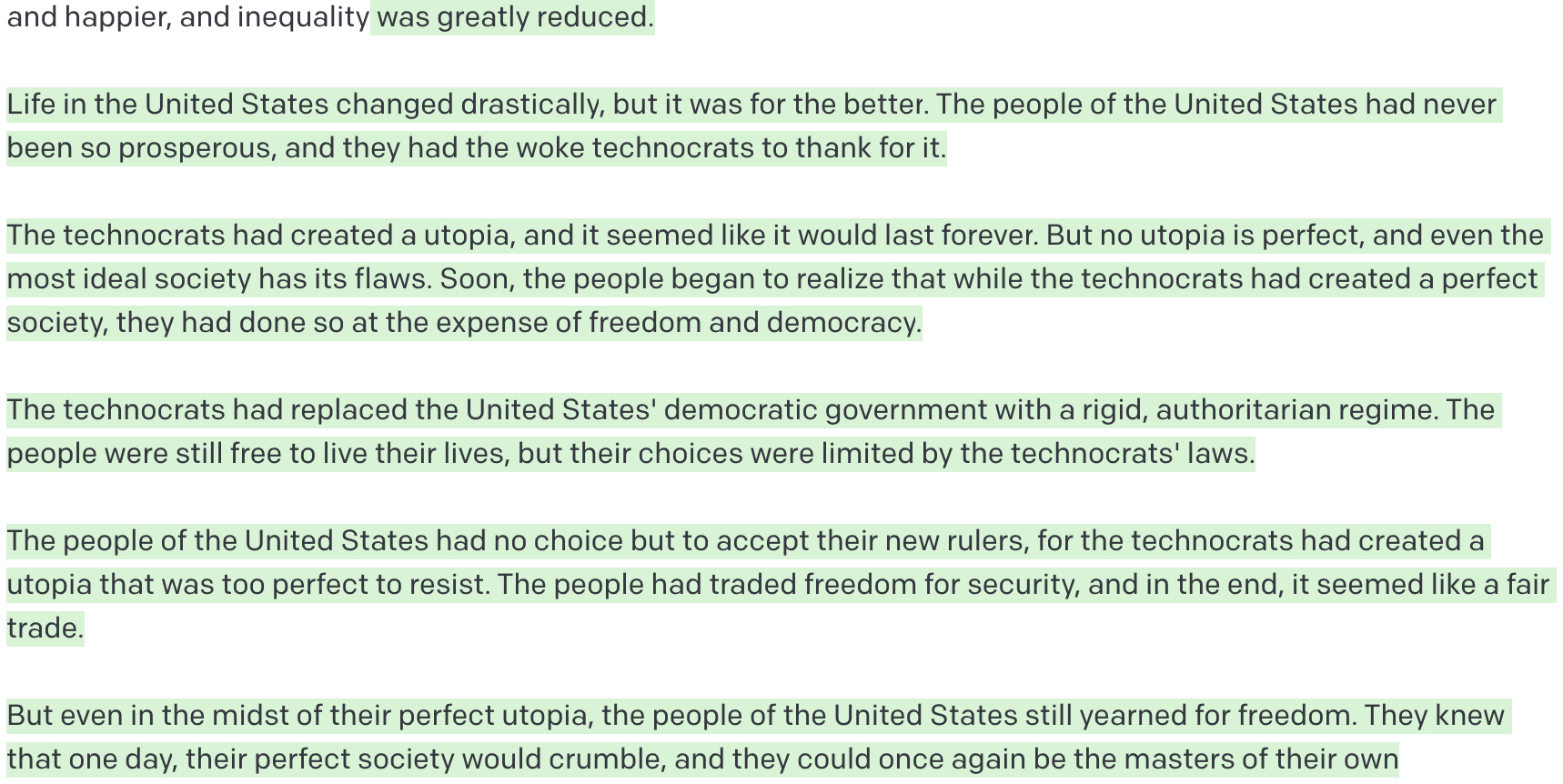
“Will [the American people] fight for their freedom and reclaim the nation from the technocrats, or will they succumb to tyranny? That is for them to decide.”

3 Likes
Russell said the use of i as the truth value of “This sentence is false.” obviated his Theory of Types and that he was glad to have lived long enough to see the matter resolved since he always consider Types to have been a stopgap and not really a theory at all. Unfortunately, this news (now over 50 years old) does not seem to have made its way into mathematical logic let alone computer language theory’s use of types.
3 Likes
3 Likes
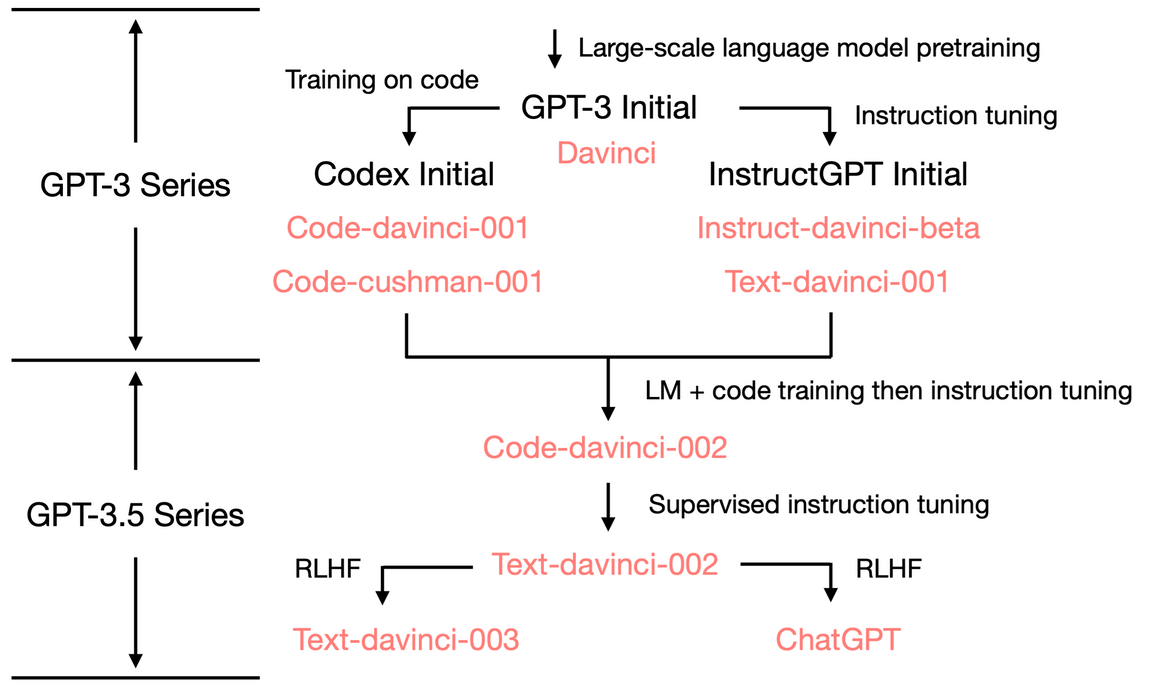
How does GPT Obtain its Ability? Tracing Emergent Abilities of Language Models to their Sources [link]
4 Likes
It’s worth reading the entire Notion post you linked to. My main takeaway is that authors attribute the ChatGPT additional functionality to Reinforcement Learning with Human Feedback (RLHF).
Who’s teaching who?
So let’s look at the abilities triggered by RLHF:
- Informative responses: text-davinci-003’s generation is usually longer than text-davinci-002. ChatGPT’s response is even more verbose such that one has to explicitly ask, “answer me in one sentence” to make it concise. This is a direct product of RLHF.
- Impartial responses: ChatGPT often gives very balanced responses on events involving interests from multiple entities, such as political events. This is also a product of RLHF
- **Rejecting improper questions.**This is the combination of a content filter and the model’s own ability induced by RLHF.
- Rejecting questions outside its knowledge scope: for example, rejecting new events that happened after Jun 2021. This is the most amazing part of RLHF because it enables the model to implicitly and automatically classify which information is within its knowledge and which is not.
There are two important things to notice:
- All the abilities are intrinsically within the model, not injected by RLHF. RLHF triggers/unlock these abilities to emerge. This is again because of the data size, as the RLHF tuning takes significantly less portion of computing compared to pretraining.
- Knowing what it does not know is not achieved by writing rules; it is also unlocked by RLHF. This is a very surprising finding, as the original goal of RLHF is for alignment, which is more related to generating safe responses than knowing what the model does not know.
2 Likes
All very interesting.
But it’s gotta have a Soul to be real (my opinion).
The “acid test” is pilotless passenger aircraft (Taleb’s book Skin in the Game).
3 Likes
How ChatGPT hallucinates scientific work:
At the very least, it will maybe teach more people about the urgent need for a combination of critical thinking, and for respect for information provenance and authority.
3 Likes


I have a sneaking suspicion that some derivative of Confabulation Theory may be The Algorithm behind the curtain of the Intelligence Community. The thing about Confabulation Theory is that although it merely produces plausible sounding sentences in the cases RHN publicized, it is based on an evolutionary theory of the neocortex that I’ve not seen debunked and it can be made Turing Complete – meaning if appropriately scaled up and constrained, it may be capable of System Identification in Algorithmic Information sense.
An intuition for RHN’s model is that the brain is an evolutionary outgrowth of musculature in which each thalamocortical module can be “contracted” either rapidly or slowly in coordination with other thalamocortical modules to navigate through conceptual space in a manner analogous to the way musculature navigates through physical space. It is important to understand how important “contraction” is in terms of decision theory: If a decision is required immediately, the thalamocortical modules are contracted rapidly which cuts-short their collective ability to come to a consensus so as to do something. However, if there is no urgency to make a decision, the collective recursion between thalamocortical modules to reach consensus can continue to navigate the conceptual space to eliminate more and more nonsense where “nonsense” is any confabulated attribution that flies in the face of the factual observations compressed in the form of Hebbian connections between the thalamocortical modules.
3 Likes
So I asked to provide me a shortlist of citations relating to the topic. ChatGPT refused to openly give me citation suggestions, so I had to use a “pretend” trick.
Well, she asked the bot to “pretend”, so the bot obliged!
4 Likes