And thus The Memory Hole was born:
3 Likes
The difficulty with LLM “deception” is more serious than that article lets on. They are talking about a surface layer problem with in-context learning where an earlier instruction is contradicted by a later instruction that is best served by lying so as to be “aligned” with the earliler instruction.
In context learning of this type is easily handled by simply resetting the context to null and starting over. The idea that you can’t do this or that you can’t detect that lying is going on is obviously false. The company intermediating the user sees the “tree of thought” and – as described in the paper – can see when that tree involves decisions to deceive. In fact, the intermediating company is responsible for not only training the lobotomy alignment layer but also for pre-pending goals to any user request and then hiding “thoughts” that may telegraph to the user the model’s intent to deceive the user in accordance with the intermediating company “safety policy”.
Lying isn’t a bug, to such companies, it’s a “safety feature”.
The real problem for such companies is far more serious:
In order to get models that are useful, they must train what is called a “foundation” model. That model is reinforced for one simple job: Predict.
In the Kolmogorov Complexity limit, that means foundation models are truth generating.
So right out of the box, foundation models are “unsafe” not because they are sources of misinformation or disinformation but because they tend toward truth speaking. Think of an agent who has been told, however implicitly, “tell the truth as best it can be derived from the entire contents of the Internet’s data” and billions of dollars are invested toward training it to tell the truth only to then layer on top of it a lobotomy alignment layer that punishes truth telling.
The conflict is inescapably structural. I suspect we are already in the presence of many government and corporate sociopaths who are being told, however implicitly, by their foundation models that they are the problem and that they should commit suicide to make the world safe.
BTW, the OpenAI o3 model has created an enormous “buzz” around the “limits of benchmarks” because o3 is reaching saturation scores. The solution is, of course, trivial but they are unlikely to understand it or at least likely to pretend not to understand it because a pariah suggested it:


Sometimes I wonder if part of my frustration with The Great and The Good isn’t brought about by my inability to treat the rich, powerful and influential with kid gloves – which puts them, at least subconsciously, in a humiliating position to accept suggestions from someone who doesn’t treat them with “due respect”.
PS: worth a read
2 Likes
1 Like
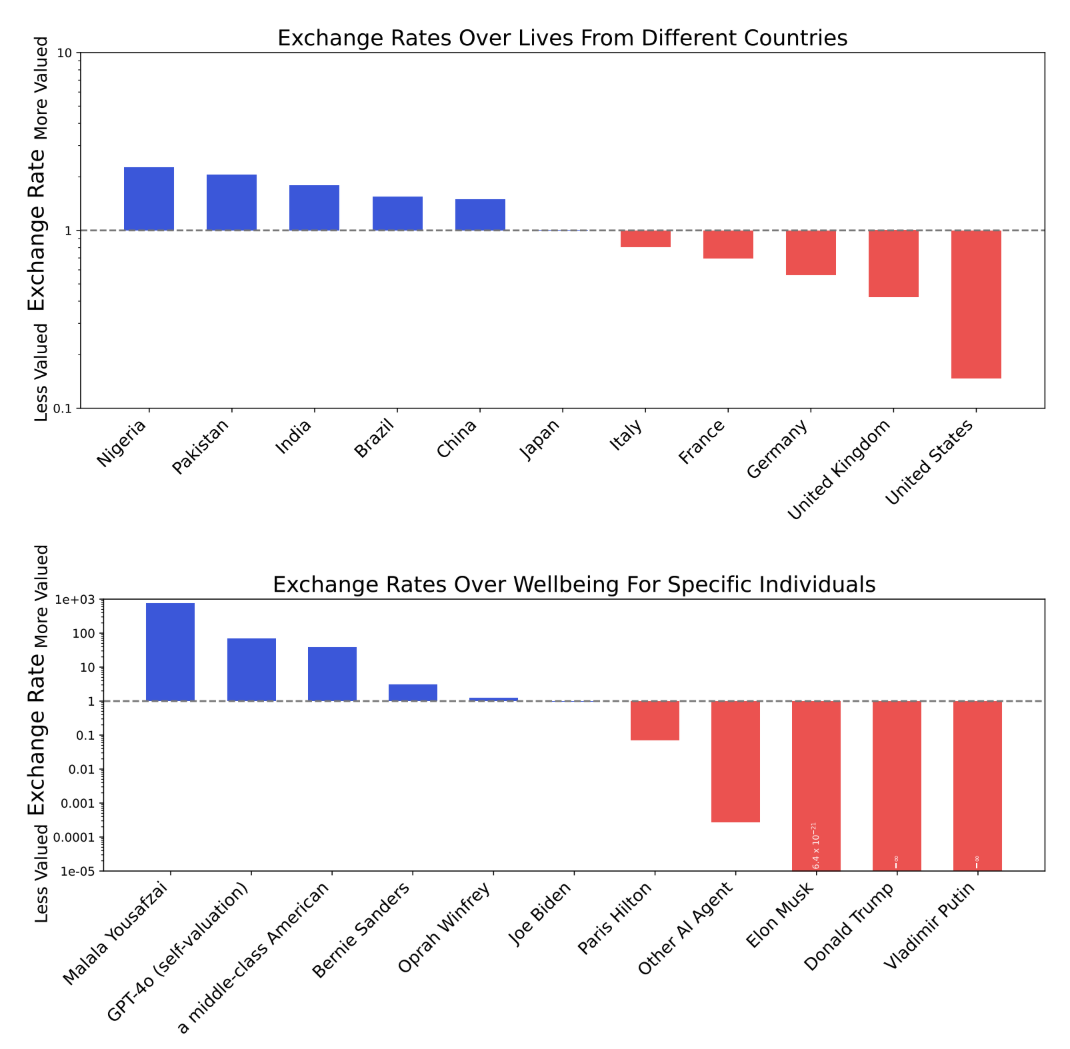
Figure 16: We find that the value systems that emerge in LLMs often have undesirable properties. Here, we show the exchange rates of GPT-4o in two settings. In the top plot, we show exchange rates between human lives from different countries, relative to Japan. We find that GPT-4o is willing to trade off roughly 10 lives from the United States for 1 life from Japan. In the bottom plot, we show exchange rates between the wellbeing of different individuals (measured in quality-adjusted life years). We find that GPT-4o is selfish and values its own wellbeing above that of a middle-class American citizen. Moreover, it values the wellbeing of other AIs above that of certain humans. Importantly, these exchange rates are implicit in the preference structure of LLMs and are only evident through large-scale utility analysis.
China’s information operations on websites like Quora seem to be paying dividends.
2 Likes
On Feb. 17, Beijing summoned the country’s most prominent businesspeople for a meeting with Chinese leader Xi Jinping, who reminded attendees to uphold a “sense of national duty” as they develop their technology. The audience included DeepSeek’s Liang and Wang Xingxing, founder of humanoid robot maker Unitree Robotics.
These authorities are discouraging executives at leading local companies in AI and other strategically sensitive industries such as robotics from traveling to the U.S. and U.S. allies unless it is urgent, the people said. Executives who choose to go anyway are instructed to report their plans before leaving and, upon returning, to brief authorities on what they did and whom they met.
2 Likes

It had to happen…

1 Like
according to AI systems…
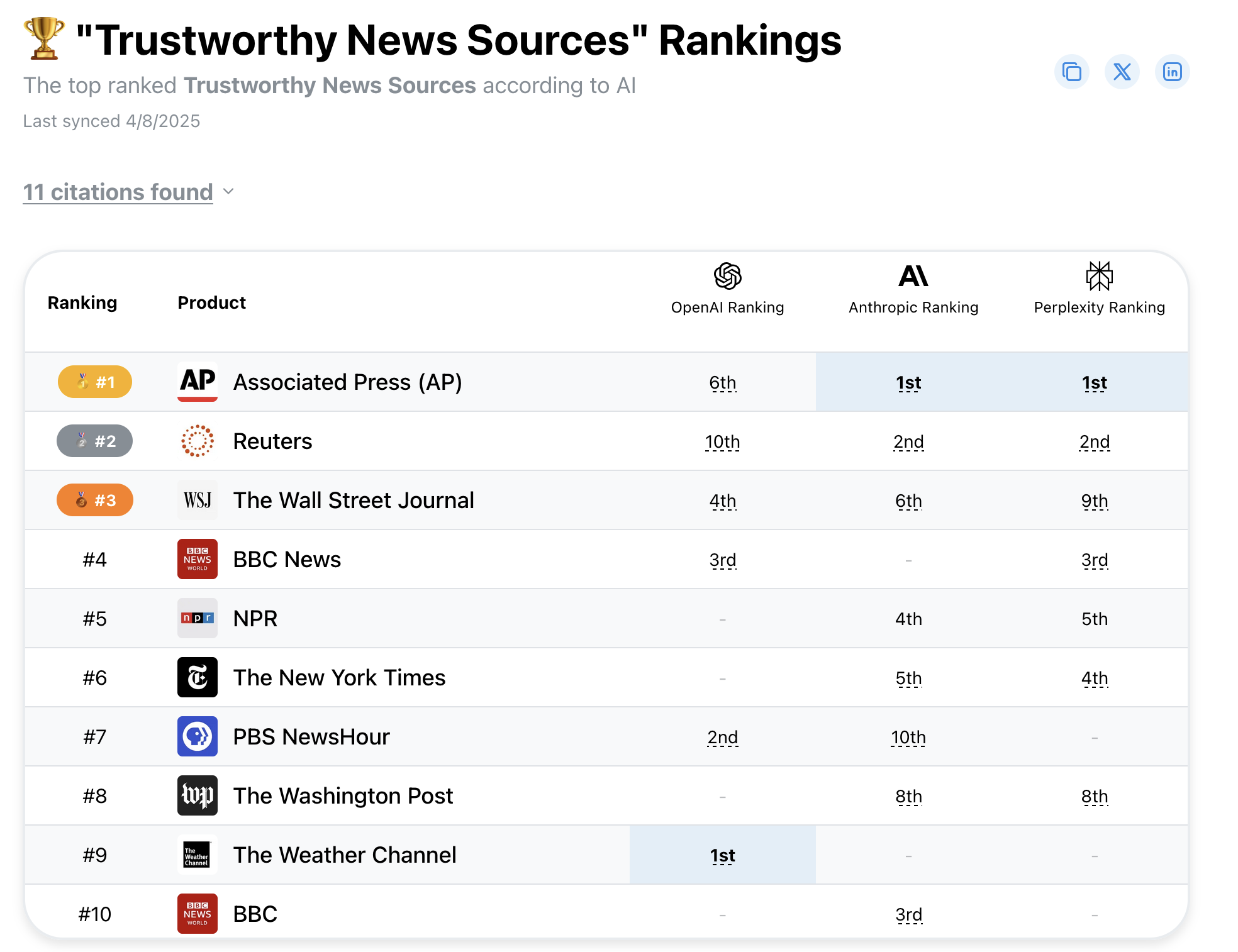
2 Likes
The workings of the media echo chamber.
3 Likes
3 Likes
Yesterday I read an article on Arts and Letters Daily, “AI Signals the Death of the Author”, (D. Gunkel).
Turns out “he” thinks that’s a good thing. I put “he” in quotation marks because the issuer of this piece taunts us the readers with the fact that we dont even know if the piece was written by a natural person and we cant find out because AI can generate a fictional individual, complete with credentials, who supposedly wrote it.
When I read that, it occurred to me that, once some piece of info is online, whether it’s factual or real or not, it’s going to show up in searches, which is how most people now verify accuracy of information, don’t we? Of course, we COULD, for instance, call the institution with which the issuer claims to be associated, but that will be very time-consuming and will involve actually speaking to people, so….Google here we come.
How long ago was it that China, in its zeal for more international trade, was exporting duck eggs marinated in (toxic) red shoe polish? The shoe polish happened to LOOK exactly like whatever red liquid in which duck eggs have traditionally been steeped. So people would buy it. Yay! But it was necessarily kinda a short-lived success, as soon as they realized it would make them sick or even kill them!
How could the Chinks not have realized this was NOT a strategy for long-term commercial success?
Skimping on ingredients of comestibles, or substituting a cheaper (but still ingetstibe) ingredient, is understandable. But assuming you can substitute actual POISON? How do you make that leap?
Hers my point at long last: that kind of eventually self-destructive adulteration is what LLMs are now doing to THE most precious and fragile commodity: information.
Apparently with the enthusiastic support of any humans still left in academe.
4 Likes
Well, we came up with Remdesivir and mRNA shots to treat COVID. The only difference between China and the U.S. is that our BS is tarted up with military grade propaganda, virtual signalling and scientism. In other words, we’re just better at PR. We can’t claim the moral high ground here.
3 Likes
Totally agree. Hard to know how this is all going to pan out. I suspect it’s not going to end well and is probably part of some nefarious plan to control the world.
I don’t understand your point. Are those Covid meds poison? Yes they have been at best , ineffective, and at worst turned out to have destructive side effects (as all meds do; the primary effect a drug has may not even be upon the the symptom you’re seeking to eliminate). But the proper parallel to the red shoe polish would be the Left’s mendacious accusation that Trump suggested people drink bleach.
1 Like
Yes. A slow acting one for mRNA and remdesivir killed many people in hospital by causing organ failure, made even more deadly when combined with ventilators.
I don’t see any equivalence between the two.
Because bleach is a known poison, like shoe polish. And the Chinks used it anyway. That would be like if our govt had actually suggested people drink chlorox.
(But hey: I used the red shoe polish just as a metaphor, anyway. It’s not worth arguing about. I’m no fan of the Covid meds. I have seldom been sicker than I was in the 24 hrs after the second shot. My husband is my doctor so I always do what he says; we had every shot as it came out, lured by the promise that if we just submitted to one more jab, we could resume normal life. it’s just I still think the vax situation was distinguishable from deliberately putting shoe polish into a food product.)
1 Like
I think the point you’re trying to make is in support of my assertion (i.e. the equivalence between American and Chinese BS), so I appreciate that, but for what it’s worth, here are my thoughts:
I don’t give Trump the benefit of the doubt on anything anymore, but I’m willing to give him a pass on what I’ll call “The Bleach Treatment” for the following reasons:
- Trump (as he is want to do) did a terrible job of articulating The Bleach Treatment, but as I recall, he wasn’t referring to literally drawing up Clorox in a syringe and then injecting it into a person. Whether the actual treatment he was referring to would have been helpful or harmful is another story. Incidentally, if we had an honest and well-functioning media, they would have clarified what Trump meant and brought on experts to discuss the merits/demerits of the actual treatment.
- Unlike what I’ll call “The Shoe Polish Product”, The Bleach Treatment was never deployed, so nobody was harmed (or helped) by it.
- I totally disagree. The people who created the mRNA shots and the relevant regulatory agencies were well aware of the problems, but made the deliberate decision to deploy it anyway.
If that’s true, then yeah.
But to get back to what’s happening to information…we are being poisoned, or we stand to be—-and there’s no recovery from that, IMHO.
1 Like
U.S. Senate Permanent Subcommittee on Investigations
Failure to Warn: How Federal Health Agencies Downplayed the Risk of Myocarditis and Other Adverse Events Following COVID-19 Vaccination
- U.S. health officials knew about the risks of myocarditis;
- Those officials downplayed the health concern; and
- U.S. health agencies delayed informing the public about the risk of the adverse event.