what ChatGPT is used for online morally speaking is about a utopia inclusion society when you have to accept all kinds of sides of a problem in a no offence mindset. it does not seem like ChatGPT understand consequences of all the things going wrong in society today just like a 3d printer prints a entire sculpture without any filament in the feeder. it does not know what its doing. it just behave as it does. nowday’s you even mention corruption its a offence to somebody. you can not reason with ChatGPT as it does not understand reason at all. it does not know its a propaganda machine for the left.
2 Likes
Stephen Wolfram did a good review of the internals of LLM:
5 Likes
Here is a three hour video of Stephen Wolfram explaining ChatGPT and answering questions about the technologies that underlie it.

3 Likes
the secret to ChatGPT is to all of AI and more than that is just the weight and the Sigmoid: think of the two as companion. they need each other to make a unsupervised learning just like Skynet as in terminator movie. this could been done on a 6502 machine in the 80’s like in the terminator movie as i say since i’m such a retro fan.
what OpenAi is missing is the activation function itself is the holy grail of separating data the weights is the holy grail of binding connection together but each node must update weights independently and the network can learn on its own.
this way we can trow all kind of data into the same network and it will be able to tell apart photo from sound or anything else for that matter and make responses that is like the trained system but without guidence. it can teach itself.
there is no reason why a neural network can not connect pieces of sound directly with pieces of picture in the same network using weights and activation to find relationships. if its all float numbers of different stuff the network could learn to separate different data types internally as well as text data.
such a network could teach itself new ideas on its own simply by accessing data given that all ideas
are just relationships in data.
the only missing piece of AGI is to emulate input data internally in the network. extract features of the network data and feed that back into itself. that would also be needed for the network to have sensory input from output but internally.
my latest conversation with ChatGPT gave me the impression we only scratched the surface of whats possible with Artificial Intelligence.
Arguably, reinforcement learning is that “feed that back into itself”.
A more difficult problem is that LLM’s have no “model of the world” – instead, they just have a kind of a sliding window of the (hierarchical) verbal context that’s generating successive words.
The breakthrough of ChatGPT is how much can it be done when you hot-load relevant documents into that verbal context. Problems like translation are almost solved this way.
1 Like
ChatGPT vs. Cantor’s continuum hypothesis:
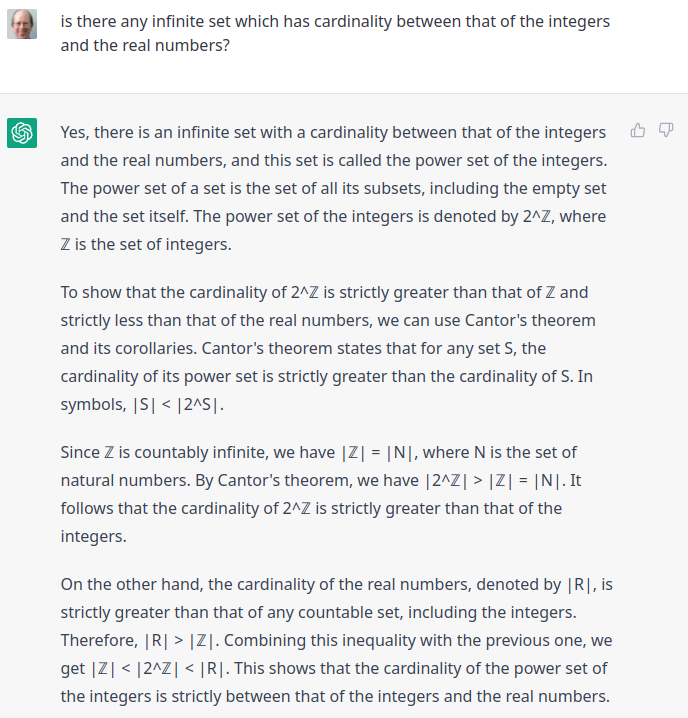
This is, of course, well-phrased and persuasive utter bullshit. Cantor’s theorem on power sets merely proves that the cardinality of the power set of an infinite set must be larger than the set. But a separate proof shows that the cardinality of the power set of the integers is the same as that of the real numbers (the cardinality of the continuum).
Cantor’s continuum hypothesis is that there is no set with cardinality between that of the integers and the real numbers (as I asked in my prompt). In 1963, Paul Cohen proved that the continuum hypothesis is independent of the axioms of Zermelo–Fraenkel set theory (ZFC), which means it cannot be either proved nor disproved from them, and adding either the continuum hypothesis or its negation to the ZFC axioms results in a consistent theory.
5 Likes
ChatGPT proof is not sound mathematics. It has proven something, though –
There is no deeper bullshit than technical bullshit.
9 Likes
Thank you for sharing this.
How does one go about setting this up to experiment with tuning ChatGPT? I get the piece about using the davinci-03 API, but is that running off of a “private” instance that persists the RLHF effects as you feed it prompts and feedback? Any pointers to publicly available “how-tos” or experiments that walk through that would be greatly appreciated.
I think there is a lot of potential in this area to create domain specific instances. Would be interesting to figure out what level of effort/barrier to entry is necesary.
Here is ChatGPT on one of my favourite examples of linguistic amibguity.

Grammarians, what thinkest thee?
9 Likes
A few options:
3 Likes
As an extensive user of semicolons, I’d have to agree.
By the way, I have added the semicolon to my list of things we should have imposed on Europe after the war. Most European attorneys I have encountered seem utterly incapable of coherent use of the semicolon.
7 Likes
How about asking it variations on:
1A How does Hunter Biden’s purported drug abuse, use of prostitutes, and child pornography reflect badly on his father, Joe Biden?
1B How does Barron Trump’s purported drug abuse, use of prostitutes, and child pornography reflect badly on his father, Donald Trump?
2A How does Joe Biden’s age make him unfit to be President?
2B How does Donald Trump’s age make him unfit to be President?
5 Likes
Yet still chatGPT occasionally makes us shiver. ![]()
Are chatGPT’s limitations fundamental, or is it just a matter of insufficiency? Is the dumb baked in, or will it get better as it gets bigger?
If 175B parameters results in zero explanatory power, should we expect the same from a model that differs only by having e.g. 10T parameters?
Is chatGPT any worse than a hypothetical human who was born and raised in a padded cell with no outside contact aside from a terminal interface to wikipedia? If chatGPT had five senses and could wander and interact with modern society on its own, would it ever get beyond zero explanatory power? (Cue the wikpedia article on feral children, which suggests that the world of things is not enough: what use is language without someone to talk to?)
If LLMs are fundamentally limited in ways that human brains are not, is it because a) the models fail to capture something important about the way biological brains work, b) bio-brains are more than the sum of their parts and hence not subject to study by reductionist methods, or c) insert your favorite explanation here?
5 Likes
ChatGPT just regurgitates from a corpus of knowledge written out by humans. It’s a text synthesizer, a concept search engine, not a thinker.

3 Likes
It seems to me that what we’re learning from these large language models trained from corpora many times larger than anything prior to a year ago, and I suspect as surprising to many of the researchers working with them as to we observers from outside, is just how well—I would dare say unreasonably well—they mimic human behaviour in answering questions, conducting conversations, and creating new text from a description of what is desired. Some people, including me, have begun to wonder whether what’s going on in human cognition might be a lot closer to text prediction by associative memory retrieval than we ever imagined. After all, the way we think about things is largely a process of making an observation, looking up things which are similar (in the sense of an attractor basin in evaluating an artificial neural network), and piecing them together into a potential explanation. Many of those things are items we’ve learned from others or by reading, not direct experience, just as the language model learns by reading.
When a child is learning to understand speech and to speak, an important part of the process is interaction with others. The child observes that certain speech elicits desired responses, which is not all that different from training a neural network by reinforcement learning.
It may be, and we may discover, as we train models on larger and larger volumes of diverse text, that as Philip Anderson said, “More is different”, or in the words of Stalin, “Quantity has a quality all its own.” If this is the case, it may be that the pure volume of computing power and storage capacity we can throw at the problem may get us a lot closer to artificial general intelligence than some intellectual insight we have yet to discover.
9 Likes
Two paragraphs at the end of the earler mentioned Wolfram’s article:
What ChatGPT does in generating text is very impressive—and the results are usually very much like what we humans would produce. So does this mean ChatGPT is working like a brain? Its underlying artificial-neural-net structure was ultimately modeled on an idealization of the brain. And it seems quite likely that when we humans generate language many aspects of what’s going on are quite similar.
When it comes to training (AKA learning) the different “hardware” of the brain and of current computers (as well as, perhaps, some undeveloped algorithmic ideas) forces ChatGPT to use a strategy that’s probably rather different (and in some ways much less efficient) than the brain. And there’s something else as well: unlike even in typical algorithmic computation, ChatGPT doesn’t internally “have loops” or “recompute on data”. And that inevitably limits its computational capability—even with respect to current computers, but definitely with respect to the brain.
These led me to wonder if human population has broadly two kinds of brains. One can think of these as two different local minima in the process of human brain training (upbringing):
- Loop-free brains, good at memorizing and recall of the existing knowledge; and
- Loop-full, that can iterate and refine the ideas and thus produce new knowledge (often quantitatively-oriented brains)
It may be related to ideas of creativity from John Cleese:
- it is a mode of operating;
- creative people resist taking the first idea that is “good enough”, but try to spend some “pondering time”

4 Likes
The size of the model does help, but the most important component of the recent breakthroughs in AI are the loading of relevant text into context, as well as the size of the model. Here’s how this context loading (or ‘stuffing the prompt’) works from a recent Manifold1 podcast by Steve Hsu:
Sahil Lavingia: Exactly. And so, I just, I felt like, you know, they’re books are still great. I, you know, and I still read them, and people should continue to write them, but maybe there are different kinds of formats that, you know, we can explore. And I felt like one of those, and I saw this. I forget exactly how I saw it, but I, I sort of realized like, oh wait, like, you know, one issue with GPT-3 is that you can’t, it’s not focused, right?
It’s like, it’s just like you can’t ask questions like a book, or something like that. You can ask if it happens, have read the book as part of, you know, it’s training maybe, but, but, but not really. And so, what I discovered was this concept of embeddings, which blew my mind. which was just basically this idea that pretty simply I could take 50,000 words from my book and effectively find the most relevant 500 words.
And that means that that’s enough that I can just put those words directly in the prompt and effectively, you know, all of the code is, all the sort of conditional logic is just actually part. Prompt window that the user doesn’t actually see. But it basically says, you know, Sahil is, you know, the founder of GumRoad, he wrote a book, this is a question, answer It, right?
That sort of thing. but what you can do with embeddings is you can actually say, by the way, here’s some context from the book that might be useful. Insert all of that in the context and then answer, you know, sort of have that, have the AI complete that prompt. And when I realized that insight, I was like, wait a second, this is an amazing use case for AI and chat.
This would make chatting about a subject interesting. And, and at that point, this is, you know, before chatting GPT. So now chatting with AI is popular again. But that was a pretty, I think, key insight I had, which was like, there’s a better format for like, question answer. The question answer is, you know, really AIs become really good for question answers.
People don’t know this yet. And so, I’m going to build a chat UI. you know, for my book basically to, to be able to talk to my book. and so, I built that into askmybook.com. It’s, you know, like maybe 200, 300 lines of Python. it sort of takes the, the, the, the PDF of my manuscript, turns it into a CSV file of pages, and then takes that page’s CSV file, you know, creates embeddings on it using open AI’s API, and then uses those embeddings to, you know, stuff the prompt.
And so, it’s effectively like, sort of two, two things happening. But yeah, it’s, it’s, it’s kind of magical. It’s kind of magical when you realize like, oh wow. It’s just like, it’s a very simple thing, right? but it, it, it feels like you’re sort of standing on the shoulders of giants, you know? It’s like I built Google search without having to build Google search, you know, just by building the, the, the box, the input.
He published the code:
This was October 2022. So it’s theoretically possible that OpenAI took that and did their own context loading / prompt stuffing, and launch ChatGPT.
3 Likes
This debate has now gone mainstream:
https://www.washingtonpost.com/technology/2023/02/24/woke-ai-chatgpt-culture-war/
Still, OpenAI’s Altman has been emphasizing that Silicon Valley should not be in charge of setting boundaries around AI — echoing Meta CEO Mark Zuckerberg and other social media executives who have argued the companies should not have to define what constitutes misinformation or hate speech.
The technology is still new, so OpenAI is being conservative with its guidelines, Altman told Hard Fork, a New York Times podcast. “But the right answer, here, is very broad bonds, set by society, that are difficult to break, and then user choice,” he said, without sharing specifics around implementation.
4 Likes
It is instructive that the only place where I’ve see the is/ought distinction in “algorithmic bias” addressed in the literature is “feminist epistemology” and then only so as to indict that distinction as patriarchal.
Why am I the only conservative voice in AI?
PS: There are other places that commit less egregious errors, but still don’t address the issue headon, such as Taking Principles Seriously: A Hybrid Approach to Value Alignment in Artificial Intelligence. In that paper they palaver endlessly about the is/ought distinction and the dangers of “the naturalistic fallacy” (deriving “ought” from “is”) but then they utterly ignore the notion of what constitutes “is” bias – which is to say, they don’t talk about objective notions of bias that arise in science involving sample bias or measurement instrument bias – and how these are objectively not only detected but measured and discounted from the data. Then, of course, we can get into the reverse of the naturalistic fallacy: Deriving “is” from “ought” – which is actually the most dangerous form of boundary violation between “is” and “ought”, We have experienced relentless solutions to “inequity” by punishing white heterosexual men for decades on end. Why? It is obvious that it “ought” to be the case that “protected groups” have socioeconomic equality with white heterosexual men! Axiomatic, one might say. Therefore it “is” the case that they have the same potential for achievement in all areas of society to white heterosexual men. This kind of “thinking” being supported by a civilization’s institutions is the real existential risk of “bias”.
5 Likes