For more than 50 years, I have loved to prepare and explore big databases. It has felt closer to a vocation than a profession. Don’t ask me why. The “aha!” moments are vanishingly rare, lost among the days, weeks, and months spent on tasks that meet every definition of “tedious.” But I long ago stopped farming out these tedious tasks to research assistants because I realized that, for me, they were fun and that giving those tasks to research assistants was reducing the satisfaction I found in my work.
The oddest part of this odd vocation is that in recent years I have become as absorbed in the problems of preparing databases for analysis as in exploring the data’s implications. Most people have a rough understanding of what the word “exploring” means when it comes to data analysis. But unless you work directly with databases, you are unlikely to realize how much of the iceberg is below the surface. To give you an idea, preparing the seven new variables in the data file I am about to describe took around 300 hours of work.
Typically, all this preparation is used by a researcher or team of researchers for a single study and never used again. Sometimes this is unavoidable because a database is so specific to a particular issue that it has little utility for anyone else. But over the years, I have prepared databases that have potential for exploring many topics that I did not. I am thinking especially of the databases I prepared for Human Accomplishment, Coming Apart, and Facing Reality, plus a few others that I assembled but never used for published work.
Over the next year or so, I plan to remedy this situation, sharing databases that I hope can be useful to others. But I will also post some new data files that can inform entire classes of analyses—hence the title of the series, “Data Tools.”
Charles Murray is an amazing thinker with a strong grasp on the reality of the world we live in. If you haven’t watched it, I recommend this June 2021 dialogue with Glenn Loury.
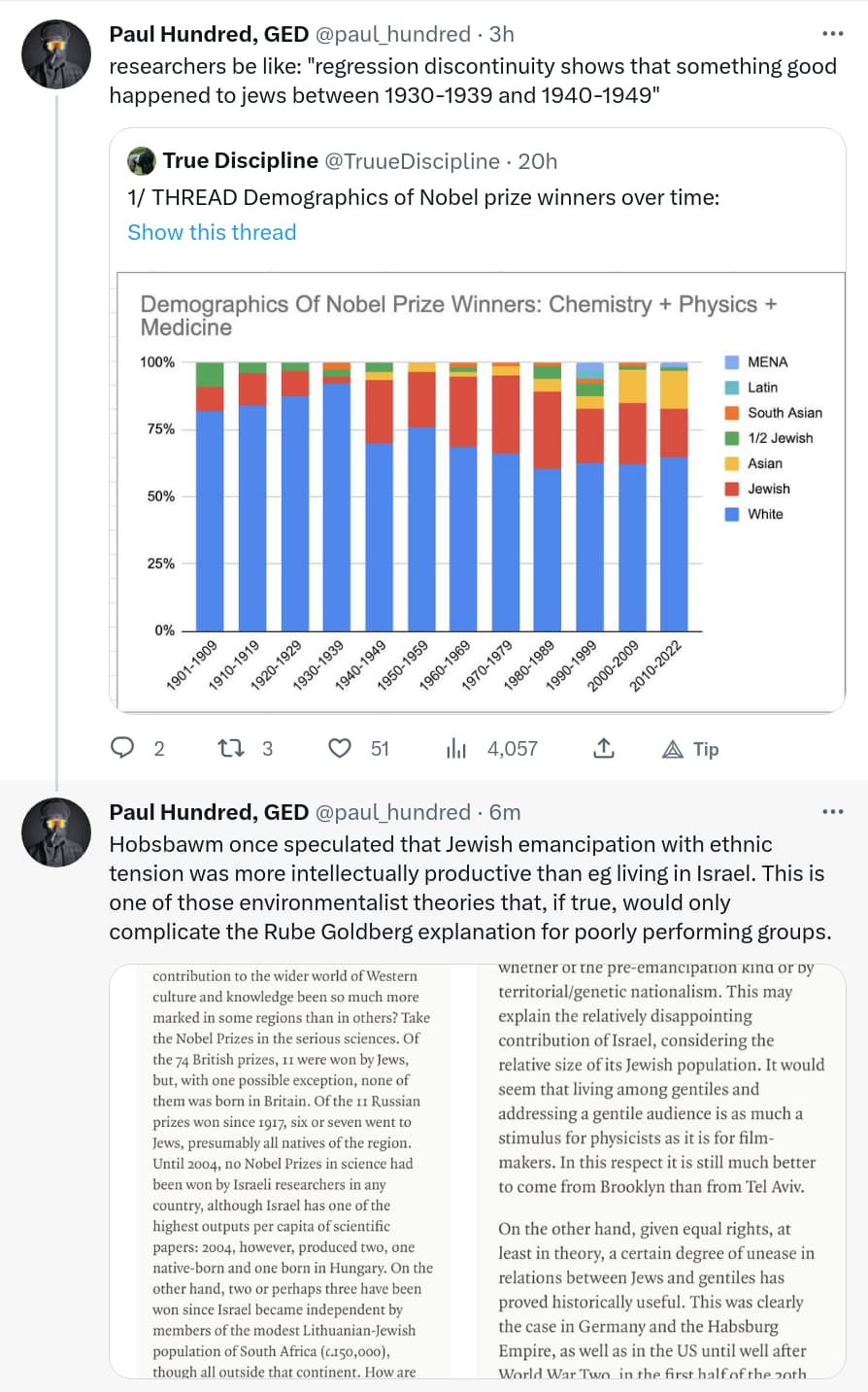
I wonder if in “Human Accomplishment”, Charles Murray addressed the “regression discontinuity” in Nobel prize winners over time that Paul Hundred, GED, rather humorously notes.
Murray’s github database may be a good addition to my Laboratory of the Counties collection. Murray’s, based on PUMA aggregation rather than county aggregation, is more in line with the trend toward “privacy protection”. I did attempt to get someone associated with the AEI interested in backing a lossless compression prize based on the Laboratory of the Counties as a way of entrapping the social pseudo-scientists into a fair contest but, there is a slight problem with a fair contest in sociology from the AEI’s point of view: It might say things their underwriters don’t like. In fact, I’m almost certain it would do so.
I will note, with some cynicism, that the privacy of individuals being most-protected is that of outliers in their counties – meaning that they likely wouldn’t be in those counties were it not for government enforced “diversity” overriding the consent of the local military-aged men.
I also note that Murray basically says what Charlie Smith told me about founding the DoE’s EIA: That the vast majority of the work is in “data cleaning” or what Murray calls “preparation”, and the minority in actual analysis (including Tukey-style “exploration”). What I told Charlie about compression prizes is that the time and effort going into “data cleaning” can be subsumed by simply letting people model the “cleaning” process. There is always the difficulty of dealing with “meta data” and other aspects of provenance in the “interpretation” of data that includes source bias. You may as well lay your cards on the table in the form of algorithms that “clean” rather than leaving it up to the endless sophistry of “academic discourse”.
Here are some less well-known databases that may be of interest and offer counter-narrative perspectives:
The Sentencing Project: Provides data and research on issues related to criminal justice reform and advocacy.
Media Cloud: A project that tracks media coverage and helps analyze trends and relationships in news coverage.
Database of Political Institutions: Provides data on political institutions, elections, and political parties from around the world.
Global Terrorism Database: Provides information on terrorist events that have occurred around the world since 1970.
The COVID Tracking Project: Provides data on the spread and impact of COVID-19 across the United States.
OpenSecrets.org: Tracks money in politics and provides data on political contributions and lobbying efforts in the US.
Mapping Police Violence: Provides data on police violence and use of force in the US.
The World Inequality Database: Provides data on trends in income and wealth inequality from around the world.
The Humanitarian Data Exchange: An open platform for humanitarian data sharing, allowing access to data on humanitarian crises.
The Environmental Justice Atlas: Provides data on environmental justice issues around the world, including resource extraction, pollution, and climate change.
These databases may offer perspectives and data that are not often highlighted in mainstream sources, and may provide valuable insights for research and analysis.
It depends on what you mean by “counter-narrative”, but here are a few suggestions for obscure databases:
The Internet Archive’s Wayback Machine - an online archive of web pages dating back to 1996. It can be useful for researching websites that may have changed or been removed since their creation.
The Bureau of Justice Statistics provides crime statistics on a variety of topics, including victimization, arrest data, and court statistics.
The Global Terrorism Database, a project of the National Consortium for the Study of Terrorism and Responses to Terrorism (START), provides detailed information on terrorist attacks from around the world since 1970.
The National UFO Reporting Center, a database of UFO sightings reported by witnesses, dating back to the early 20th century.
The Dark Web Database, a database of websites that can only be accessed using the Tor browser, where illegal activity such as drug trafficking, human trafficking, and other cybercrimes are reported.
It is important to note that not all “counter-narrative” databases may have a factual basis, so it is important to evaluate the sources and evidence supporting the information presented.
Try IQ and The Wealth of Nations or contact the authors directly. I believe Richard Lynn is still with us but he was born in 1930 so he may pass any day. Steve Sailer is another decent resource for anti-narrative data from obscure sources. Another is Emil O. W. Kirkegaard. But we’re all turning gray while the “narrative” gets automated with nightmarish demonology like ChatGPT.
See, this is why I keep trying to get people in the Realist camp to stop all their palavering – including such landmark books as the aforelinked – and start accumulating a canonical dataset subject to the lossless compression criterion incentivized by incremental prizes for improvements thereof:
If you don’t have a clear benchmark metric for Reality – in the form of a unified macrosocial model driven by data – that can be advanced with each new statistical study, and monetary incentives for those advancements, you’re just playing Sisyphus to the social pseudosciences boulder.
May be downloaded from “Cfacts 2021”, which is a Zipped archive containing the spreadsheet in OpenDocument (.ods) and CSV (.csv) formats. The spreadsheet includes the following data from these sources.
Country Properties Database
Data Sources:
CIA-WF: CIA World Factbook 2003
http://www.cia.gov/cia/publications/factbook/
EF Heritage Foundation "2004 Index of Economic Freedom"
http://cf.heritage.org/index2004test/
FH Freedom House "Freedom in the World 2015"
https://freedomhouse.org/report-types/freedom-world
https://freedomhouse.org/sites/default/files/Individual%20Country%20Ratings%20and%20Status%2C%201973-2015%20%28FINAL%29.xls
https://freedomhouse.org/sites/default/files/Individual%20Territory%20Ratings%20and%20Status%2C%201973-2015%20%28final%29.xls
FSI The Fund for Peace. Failed States Index 2006.
http://www.fundforpeace.org/programs/fsi/fsindex.php
GPI Vision of Humanity. Global Peace Index 2007.
http://www.visionofhumanity.com/introduction/index.php
IDB U.S. Bureau of the Census International Data Base 2003
http://www.census.gov/ipc/www/idbnew.html
IPRI International Property Rights Index
http://internationalpropertyrightsindex.org/index.php
IQWN Lynn Richard and Tatu Vanhanen. IQ and the Wealth of Nations.
Westport CT: Praeger 2002. ISBN 0-275-97510-X.
http://www.rlynn.co.uk/pages/article_intelligence/t4.htm
PEW_RPL Pew Research Center, Religion & Public Life,
Table: Muslim Population by Country
http://www.pewforum.org/2011/01/27/table-muslim-population-by-country/
PNM Barnett Thomas P. M. The Pentagon's New Map.
New York: G.P. Putnam's Sons 2004. ISBN 0-399-15175-3.
WPR World Population Review, “Murder Rate by Country 2021”
https://worldpopulationreview.com/country-rankings/murder-rate-by-country
SAS Small Arms Survey, 2017
http://www.smallarmssurvey.org/fileadmin/docs/Weapons_and_Markets/Tools/Firearms_holdings/SAS-BP-Civilian-held-firearms-annexe.pdf
Fields:
name Country name CIA-WF
population Most recent population CIA-WF
population_growth_rate Population growth rate per annum CIA-WF
lifexp Life expectancy total population CIA-WF
fertility Children born per woman CIA-WF
median_age Median age total population CIA-WF
gdp Gross domestic product purchasing CIA-WF
power parity (PPP)
gdp_growth_rate GDP growth rate per annum CIA-WF
gdp_per_capita GDP per capita (PPP) CIA-WF
iq Mean IQ (positive if measured IQWN
negative if estimated)
gini Income distribution (Gini index) CIA-WF
region Geographical region CIA-WF
FH-pr Political rights index (1-7) FH
FW-cl Civil liberties index (1-7) FH
FH-free Composite freedom status FH
"Free" "Partly Free" "Not Free"
EF-index Economic freedom score (1-5) EF
EF-category Economic freedom category EF
"Free" "Mostly Free"
"Mostly Unfree" "Repressed"
EF-trade Trade policy (1-5) EF
EF-fiscal Fiscal burden (1-5) EF
EF-intervention Government intervention (1-5) EF
EF-monetary Monetary policy (1-5) EF
EF-investment Foreign investment (1-5) EF
EF-banking Banking and Finance (1-5) EF
EF-wages Wages and Prices (1-5) EF
EF-property Property rights (1-5) EF
EF-regulation Regulation (1-5) EF
EF-informal Informal market (1-5) EF
core_gap Core ("C") or Gap ("G")? PNM
FSI-rank Global rank FSI
FSI-demo Mounting Demographic Pressures FSI
FSI-movement Massive Movement of Refugees and IDPs FSI
FSI-venge Legacy of Vengeance - Seeking Group Grievance FSI
FSI-flight Chronic and Sustained Human Flight FSI
FSI-uneven Uneven Economic Development along Group Lines FSI
FSI-decline Sharp and/or Severe Economic Decline FSI
FSI-crim Criminalization or Delegitimization of the State FSI
FSI-pubserv Progressive Deterioration of Public Services FSI
FSI-rights Widespread Violation of Human Rights FSI
FSI-secapp Security Apparatus as "State within a State" FSI
FSI-elite Rise of Factionalized Elites FSI
FSI-interv Intervention of Other States or External Actors FSI
FSI-Total Total (Sum of FSI-demo through FSI-interv) FSI
GPI-score Global peace index score (low = more peaceful) GPI
GPI-rank Rank by global peace index (low = more peaceful) GPI
IPRI-comp International property rights index composite IPRI
IPRI-lp Legal and political environment IPRI
IPRI-phys Physical property rights IPRI
IPRI-intel Intellectual property rights IPRI
IPRI-ge Gender equality IPRI
percent_muslim Percent population muslim, -0.1 means < 0.1% PEW_RPL
murder Homicide rate per 100,000 population WPR
guns Estimated number of civilian guns per capita by country SAS
P-yyyy Population mid-year yyyy IDB
1950-2050 (positive if estimated
negative if projected)
The data date to whenever I collected, extracted, and added them to the database, starting in 2004. I have made no effort to update data in columns to more recent releases. If you wish to use these raw data, it’s up to you to determine their copyright status, obtain permission, and cite accordingly. I can offer no assistance in using these data—you’re entirely on your own.