In a paper published in the 2022-12-08 issue of Science, “Competition-level code generation with AlphaCode” [Science link is flaky at this writing—often you just get black screen boilerplate, other times it works] (behind a paywall, of course), 21 authors working for Alphabet (Google’s parent company) subsidiary DeepMind report their AlphaCode system performs better at solving problems presented in coding competitions than 45.7% of human programmers in the competition, solving around 34% of the problems. Here is the abstract from the paper.
Programming is a powerful and ubiquitous problem-solving tool. Systems that can assist programmers or even generate programs themselves could make programming more productive and accessible. Recent transformer-based neural network models show impressive code generation abilities yet still perform poorly on more complex tasks requiring problem-solving skills, such as competitive programming problems. Here, we introduce AlphaCode, a system for code generation that achieved an average ranking in the top 54.3% in simulated evaluations on recent programming competitions on the Codeforces platform. AlphaCode solves problems by generating millions of diverse programs using specially trained transformer-based networks and then filtering and clustering those programs to a maximum of just 10 submissions. This result marks the first time an artificial intelligence system has performed competitively in programming competitions.
The issue of Science which featured this paper on the cover included a “front of book” popular article which is freely available, “AI learns to write computer code in ‘stunning’ advance”.
AlphaCode goes beyond the previous standard-bearer in AI code writing: Codex, a system released in 2021 by the nonprofit research lab OpenAI. The lab had already developed GPT-3, a “large language model” that is adept at imitating and interpreting human text after being trained on billions of words from digital books, Wikipedia articles, and other pages of internet text. By fine-tuning GPT-3 on more than 100 gigabytes of code from Github, an online software repository, OpenAI came up with Codex. The software can write code when prompted with an everyday description of what it’s supposed to do—for instance counting the vowels in a string of text. But it performs poorly when tasked with tricky problems.
AlphaCode’s creators focused on solving those difficult problems. Like the Codex researchers, they started by feeding a large language model many gigabytes of code from GitHub, just to familiarize it with coding syntax and conventions. Then, they trained it to translate problem descriptions into code, using thousands of problems collected from programming competitions. For example, a problem might ask for a program to determine the number of binary strings (sequences of zeroes and ones) of length n that don’t have any consecutive zeroes.
When presented with a fresh problem, AlphaCode generates candidate code solutions (in Python or C++) and filters out the bad ones. But whereas researchers had previously used models like Codex to generate tens or hundreds of candidates, DeepMind had AlphaCode generate up to more than 1 million.
To filter them, AlphaCode first keeps only the 1% of programs that pass test cases that accompany problems. To further narrow the field, it clusters the keepers based on the similarity of their outputs to made-up inputs. Then, it submits programs from each cluster, one by one, starting with the largest cluster, until it alights on a successful one or reaches 10 submissions (about the maximum that humans submit in the competitions). Submitting from different clusters allows it to test a wide range of programming tactics. That’s the most innovative step in AlphaCode’s process, says Kevin Ellis, a computer scientist at Cornell University who works AI coding.
After training, AlphaCode solved about 34% of assigned problems, DeepMind reports this week in Science. (On similar benchmarks, Codex achieved single-digit-percentage success.)
The article closes on a note of “What hath Google wrought?” caution.
The study also notes the long-term risk of software that recursively improves itself. Some experts say such self-improvement could lead to a superintelligent AI that takes over the world. Although that scenario may seem remote, researchers still want the field of AI coding to institute guardrails, built-in checks and balances.
“Even if this kind of technology becomes supersuccessful, you would want to treat it the same way you treat a programmer within an organization,” [MIT computer assisted programming group head Armando] Solar-Lezama says. “You never want an organization where a single programmer could bring the whole organization down.”
Here is blog post from DeepMind with more details about AlphaCode, “Competitive programming with AlphaCode”. The complete set of programming competition problems and solutions is posted on GitHub.
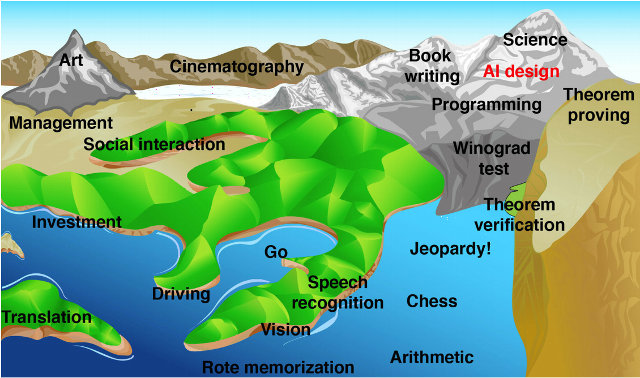
I think it’s time for this picture again, from Max Tegmark’s Life 3.0.