Ever since having been astonished by the output from generative image synthesis systems such as DALL-E 2 and text generation from large language models like ChatGPT, I’m sure I’m not the only one to have wondered, “How long before the AIs start composing music?”
Well, that wasn’t long. Google has just announced MusicLM, a generative text to music synthesiser which was trained on a data set containing five million audio clips, amounting to 280,000 hours of music. Like DALL-E 2 and ChatGPT, the desired music is described by an English text prompt, which can be as generic or specific as needed, and the result is music synthesised at 24 kHz sampling rate that matches the description. For example, here is the result from the following text prompt:
Epic soundtrack using orchestral instruments. The piece builds tension, creates a sense of urgency. An a cappella chorus sing in unison, it creates a sense of power and strength.
Here are five minutes of music produced from a prompt of just “relaxing jazz”:
MusicML can create music to accompany artworks by prompting with a text description of the image. Salvador Dali’s The Persistence of Memory:

is described in Encyclypedia Britannica as:
His melting-clock imagery mocks the rigidity of chronometric time. The watches themselves look like soft cheese—indeed, by Dali s own account they were inspired by hallucinations after eating Camembert cheese. In the center of the picture, under one of the watches, is a distorted human face in profile. The ants on the plate represent decay.
Feeding this as a prompt to MusicML causes it to compose:
These are just a few of the hundreds of examples in the page “MusicLM: Generating Music from Text” published on Google Research’s GitHub site. Visit it and be amazed.
Technical details of how the model operates and was trained are in the research paper (confusingly with the same title) “MusicLM: Generating Music From Text” posted on arXiv on 2023-01-26 with full text [PDF] linked to the paper. Here is the abstract.
We introduce MusicLM, a model generating high-fidelity music from text descriptions such as “a calming violin melody backed by a distorted guitar riff”. MusicLM casts the process of conditional music generation as a hierarchical sequence-to-sequence modeling task, and it generates music at 24 kHz that remains consistent over several minutes. Our experiments show that MusicLM outperforms previous systems both in audio quality and adherence to the text description. Moreover, we demonstrate that MusicLM can be conditioned on both text and a melody in that it can transform whistled and hummed melodies according to the style described in a text caption. To support future research, we publicly release MusicCaps, a dataset composed of 5.5k music-text pairs, with rich text descriptions provided by human experts.
Here is the MusicCaps data set for music captioning, which you can download from GitHub.
MusicML is not available for public access at this time. If and when that happens, the market for human-composed background and mood music for videos evaporates.
Here we go again—time to once again haul out the picture from Max Tegmark’s Life 3.0.
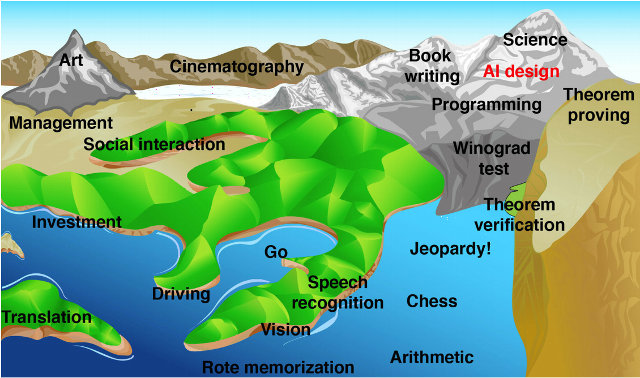
I’ll leave you with:
Slow tempo, bass-and-drums-led reggae song. Sustained electric guitar. High-pitched bongos with ringing tones. Vocals are relaxed with a laid-back feel, very expressive.
