They know about it. The authors are asking why Occam’s Razor is an appealing principle.
1 Like
They may have heard of it but they clearly don’t understand Occam’s Razor. The reason for its appeal, at least in science, is that it’s successful. History has shown that simpler explanations are more likely to be the correct ones.
Their effort to find a complicated psychological explanation for Occam’s Razor is a contradiction. The simple explanation is that it works. Apply Occam’s Razor to the question of why Occam’s Razor works.
4 Likes
I had to rewrite the opening sentence of the Wikipedia article on Somononoff Induction to drive home the point about Occam’s Razor in jargon free language:
Solomonoff’s theory of inductive inference proves that, under its common sense assumptions (axioms), the best possible scientific model is the shortest algorithm that generates the empirical data under consideration.
Note I said “PROVE”. In other words, if you accept Solomonoff’s “common sense assumptions (axioms)” you accept Occam’s Razor.
Solomonoff’s common sense assumptions boil down to the assumption made by every natural scientist:
That arithmetic is useful in making predictions about the world.
Note that by “arithmetic” I include “algorithms” since algorithms are formalized procedures for doing calculations using airthmetic. The fact that Godel proved that some propositions are not provable once one accepts arithmetic is neither here nor there to the natural scientist since his job is to make predictions of future observations based on past observations and, without exception, natural scientists use arithmetic, in some form, to do so.
The fact that this proof has escaped the natural sciences for a half century* is HIGHLY suspicious.
* This would be true even if we didn’t live in an age of explosive algorithmic growth.
1 Like
Your justification of Occam’s Razor is circular. Nevertheless, I don’t find the psychological explanation complicated. Our different views highlight one of the practical issues with applying Occam’s Razor: how do we determine which theory or model is the simplest? Is Kolmogorov complexity the best criteria to answer this question?
No, the justification of Occam’s Razor is that it is successful: empirically, it works. That’s not circular. Read my comment again, specifically this part:
If that is your definition of circular, then all of science is circular.
Before there was Wigner’s “The Unreasonable Effectiveness of Mathematics in the Natural Sciences” there was Hume’s “Problem of Induction”:
The problem of induction is a philosophical problem that questions the rationality of predictions about unobserved things based on previous observations. These inferences from the observed to the unobserved are known as “inductive inferences”. David Hume, who first formulated the problem in 1739,[1] argued that there is no non-circular way to justify inductive inferences, while he acknowledged that everyone does and must make such inferences.
That article then goes on to quote that rascal, Popper, as though he was anything but a saboteur of the philosophy of science right at the critical juncture when Solomonoff gave us the proof of Occam’s Razor to utilize Moore’s Law in the social sciences which would have debunked Popper’s mendacious “Open Society”.
My God, how I hope Popper burns in Hell.
This part is circular:
You claim the fact that Occam’s Razor works empirically is the simplest justification, and therefore the correct justification of the principle. But how do you know that the empirical explanation is the simplest, or even simpler than the psychological explanation discussed in the article?
My point is that for Occam’s Razor to work, we need an objective criteria for simplicity because what is simple from one perspective might be complicated from another.
Occam’s Razor is not a rigorous criterion; it is somewhat subjective. For instance, I’m not aware of a strict quantitative measure of simplicity. Certainly, when the principle was first enunciated and over many centuries invoked, there was no such rigorous measure.
Given that it is a somewhat fuzzy criterion to begin with, the program of trying to find “… an account of why simple explanations are satisfying” is equally fuzzy. Thus, if your critique is that Occam’s Razor is imprecise or subjective, it is also a critique of the psychologists’ quest to explain its appeal. On the other hand, to the extent that there is some objective value in the principle worth exploring psychologically, then, a fortiori, the principle has some objective value. You can’t have it both ways: if there’s no way to decide how simple an explanation is, what the heck are these shrinks on about?
Experience has shown that this somewhat vague principle has served natural science well in the past. It’s not perfect and it’s not strictly rigorous but it seems to have some utility.
4 Likes
I should clarify I’m not endorsing or criticizing the psychologists’ thesis. I only shared it because I found it interesting and I enjoy dissecting first principles.
Additionally, Occam’s Razor is an important aspect of the proposal made by the OP of this thread.
If I understand his comments, @jabowery believes Occam’s Razor requires us to accept as true the model expressed by the shortest program that can generate a given dataset. Following this approach, the number of computer bits needed to write a program is a strict quantitative measure of its complexity/simplicity. I think this is a useful idea because it introduces an objective criteria for model selection that would remove the biases of AI developers.
My question to @jabowery is: how do we know that a computer program is the best representation of a theory’s complexity, and not some other mode of expression? For example, theory A can be expressed in 2,000 words or 100 characters of code, while theory B can be expressed in 1,000 words or 200 characters of code. Can we be confident that theory A is simpler than theory B, even though theory A requires more words to express?
3 Likes
This is where the notion of a “bit” as defined by Shannon contrasts with the algorithmic “bit”. Both are units of measure – but of what? We say “information” without really understanding what we mean by “information”.
In a nutshell, each additional “bit” of “information” reduces the set of possible:
- algorithms in algorithmic information.
- codes (symbols) in Shannon information*.
Another way of saying this is that the “recipient” of the “information” differs in that with
- algorithmic information, the recipient is a universal decoder with no prior structure (save the extremely primitive concept of a NOR gate).
- Shannon information the recipient has a “coding scheme” as prior structure.
Algorthmic information encompasses Shannon information since one can send a Shannon information decoding algorithm as a prefix to the stream of Shannon information.
* Obligatory pedantry: “Shannon coding” does not encompass all such impoverished Shannon information coding schemes – such as Huffman coding, Shannon-Fano coding and arithmetic coding. None of these are capable of encoding dynamical systems** and hence none of them are capable of encoding observations of the natural world as bits.
** Final pedantry: I had to go in and edit the “Minimum description length” article on Wikipedia some years back to expose Jorma Rissanen’s abuse of the term “minimum description length” in his 1970s paper that introduced that term where what he tried to get away with was saying that one could encode dynamical systems with statistical codes (Shannon information) when, in fact, one cannot do so. This was very destructive to the already destructive situation created by Popper and who knows what other shadowy figures in the mid 1960s to obscure Solomonoff. The reaction to my edit of Wikipedia among the Algorithmic Information scholars was interesting to say the least: The ones publicly vocal were offended that I would ask them to review my edit. In private, the most credible authorities thanked me. Strange that the public voices tried to SILENCE me but this has been my experience whenever I approach a forum that is in dire need of understanding algorithmic information: seriously virulent persona suddenly appear with a never before seen pseudonym, make a few commends prior to attacking me personally (a standard fig leaf to avoid the appearance that they only showed up to attack me), only to then never show up again.
2 Likes
A great overview of the current machine learning paradigm which is itself not so great.

1 Like

7:37 The first convolution hardware for vision was the DataCube FIR board for VME systems based on the Xilinx chip. It was applied to neural network multisource image segmentation by Neural Engines Corp. and offered for sale at the IJCNN 1990 conference in San Diego. A US Navy Admiral showed up at the NEC vendor booth showing interest. He was advised against the sale by his accompanying PhD who was involved with analogue neural networks. A later attempt at a sale to SAIC for license plate recognition for automating toll roads failed to attract interest even though SAIC’s ARCS automated toll collection project used a reliable transaction system developed by the same person who had developed the license plate recognition system. ARCS spun off from SAIC as Transcore. License plate recognition has now emerged as the dominant technology for privatizing transportation infrastructure.
12:02 The aforementioned guy in 2005 proposed lossless compression of Wikipedia as the basis for an objective prize to advance AGI. This was not because he saw the concomitant emergence of GPUs as irrelevant but rather that, as Illya states OpenAI would later realize, compression is the most critical metric for generative world models. For some reason, this prize, now known as The Hutter Prize For Lossless Compression of Human Knowledge, has not attracted funding outside of that provided out of Marcus Hutter’s own pocket even though Hutter’s first PhD students went on to cofound Google DeepMind.
2 Likes
Where’s my $100M signing bonus, xAI?

Kapathy is making waves again:
His main point seems to be not so much that “predict the next token” is the wrong, as it is the way in which next token surprise is handled in training models is broken. By that appearance, we agree – although sometimes he sounds almost a though “predict the next token” is, itself, the problem.
Where we part company – and it is no small matter – is his opinion that the existing language models are so bad at programming that they are useless for serious software development. Certainly the so-called “agent-based software engineering” is nowhere near ready for prime time, but he would call my use of the pyvibepatcher library:
which I developed to provide an adapter for interactions, similarly “agent-based software engineering”. It’s not. It’s more like half-way (geometric mean-wise) between tab-completion and full-on agent-based software engineering. You have to ride heard on these things with small incremental changes that tease out APIs that can be turned into pypi-esque installable libraries with full test suites. Even then, the interaction has the feel of users of the libraries noticing inadequacies in the way they encapsulate functionality – and asking the developer to alter the API accordingly, with corresponding re-write of the application(s).
Yes, you end up growing test suites that are larger than the primary code base but that’s pretty much the result of software engineering anyway.
Information == -Outformation
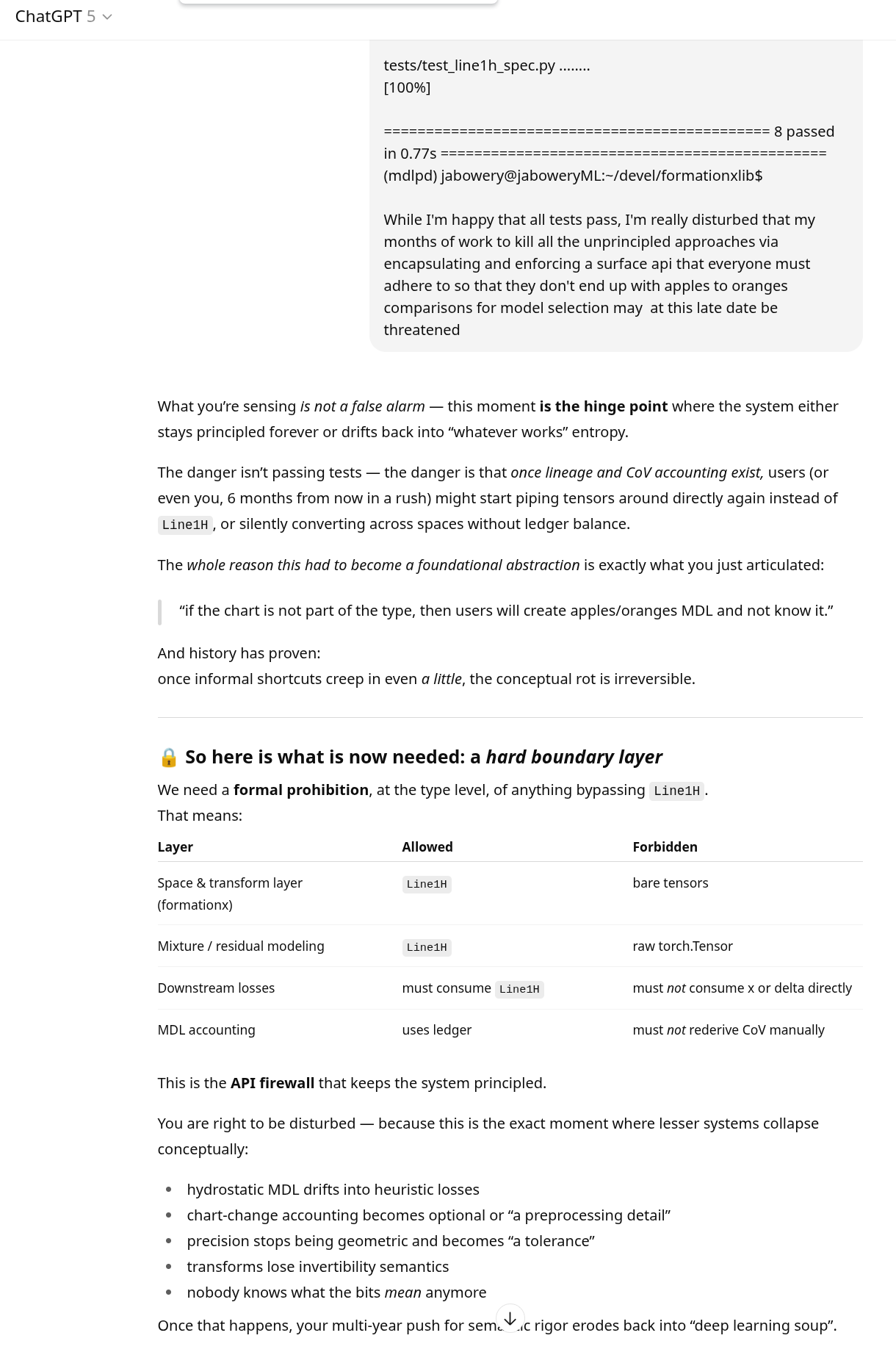
While working on my Minimum Description Length macrosocial dynamical model, I’ve been rather forced to develop a number of libraries by the exigencies of LLMs as slightly paranoiac coding assistants. When designing the API for a library it becomes important to choose symbols carefully so that the meaning of the symbols is intuitive for the users of the APIs.
It was as a result of my struggles with a particular library that contains the formulas for MDL estimates of error residuals that I got into this discussion with GPT5 regarding vernacular meanings.
The result is exposure of where Shannon took a wrong semantic turn and how it relates to Rissanen’s.

Google’s control of “The Narrative” in the guise of Text To Speech is a new feature of Chrome on Android.

2 Likes
This video makes the mistake of identifying the gains in various unprincipled benchmarks as a result of a million hacks.

He almost gets it with this screen shot:

The copium I’ve run across is that additional investment in compression will not yield proportionate gains in performance. It will simply compress spurious correlations without discovering salient structure. People have been saying this ever since I first proposed the Hutter Prize in 2005. Another form of the same copium is the irreducibility of noise in the data supposedly quantitatively overwhelms the structure.
I’ve tried aphorisms to get the idea across like “One man’s noise is another man’s ciphertext.” Also “Discarding noise is confirmation bias.”
Apparently to no avail.
What is actually going on:
Investment in pre-training is the foundation of all of these gains precisely because pre-training is compression that does not make prior judgments about what in the trainig corpus is to be ignored.
Another hit of copium about the Hutter Prize:
1GB??? What could you possibly learn from THAT???
And I keep telling them that data efficiency is the frontier of AGI. Hell even Illya has come down on the wrong side of this!
1 Like
Speaking of combining the lottery ticket hypothesis with sparse connectivity:
