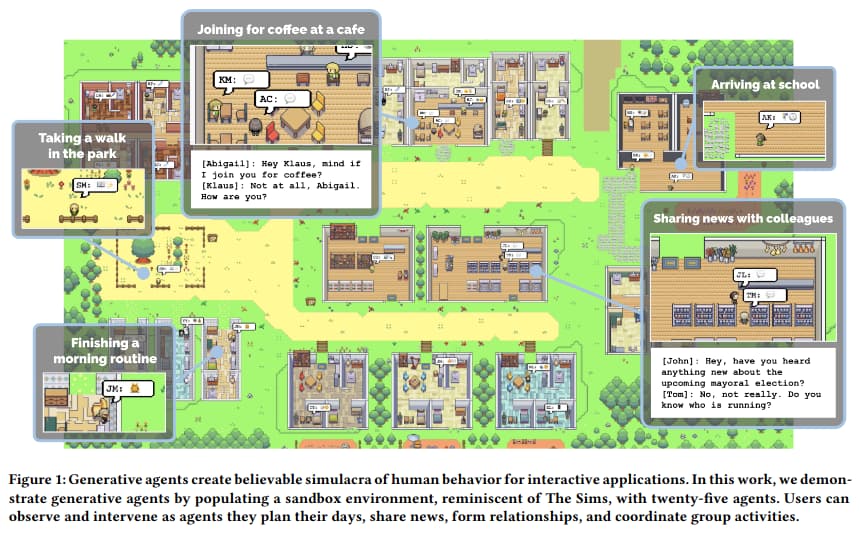
On 2023-04-07, six authors from Stanford University and Google Research posted a paper on arXiv, “Generative Agents: Interactive Simulacra of Human Behavior”. Here is the abstract.
Believable proxies of human behavior can empower interactive applications ranging from immersive environments to rehearsal spaces for interpersonal communication to prototyping tools. In this paper, we introduce generative agents—computational software agents that simulate believable human behavior. Generative agents wake up, cook breakfast, and head to work; artists paint, while authors write; they form opinions, notice each other, and initiate conversations; they remember and reflect on days past as they plan the next day. To enable generative agents, we describe an architecture that extends a large language model to store a complete record of the agent’s experiences using natural language, synthesize those memories over time into higher-level reflections, and retrieve them dynamically to plan behavior. We instantiate generative agents to populate an interactive sandbox environment inspired by The Sims, where end users can interact with a small town of twenty five agents using natural language. In an evaluation, these generative agents produce believable individual and emergent social behaviors: for example, starting with only a single user-specified notion that one agent wants to throw a Valentine’s Day party, the agents autonomously spread invitations to the party over the next two days, make new acquaintances, ask each other out on dates to the party, and coordinate to show up for the party together at the right time. We demonstrate through ablation that the components of our agent architecture–observation, planning, and reflection–each contribute critically to the believability of agent behavior. By fusing large language models with computational, interactive agents, this work introduces architectural and interaction patterns for enabling believable simulations of human behavior.
Large language models (LLMs) work by training an artificial neural network, typically with billions of connection weights, on a large corpus of text, such that the network, once trained, can respond to natural language prompts and perform tasks such as question answering, generating text to user specifications, or summarising the key points in a lengthy document. A large language model has no internal “state” recording its interaction with a client. Every response created by the model is based entirely upon the user’s prompt, plus an embedded excerpt of earlier prompts and responses (usually supplied automatically by the program the user employs to access the LLM). Interaction with a user does not modify the weights in the LLM at all, and thus novel information supplied by the user cannot be “learned” by the model. The amount of context that can be supplied in a prompt is limited, so the LLM has what amounts to only short-term memory of its interaction with a user, and if the user starts a new chat session, discarding previous interactions, the LLM starts with a blank slate.
This is, of course, very different from the way humans interact with one another in spoken or written communication. When two humans converse, they do so in the context of their earlier interactions and the topic presently being discussed. The long-term associative memory of the brain is used to steer the conversation based upon this history, which may be decades-long. What would happen if you were to couple a large language model to a search engine and associative memory database, using the LLM to formulate queries to the database and using its responses to provide context for the conversation?
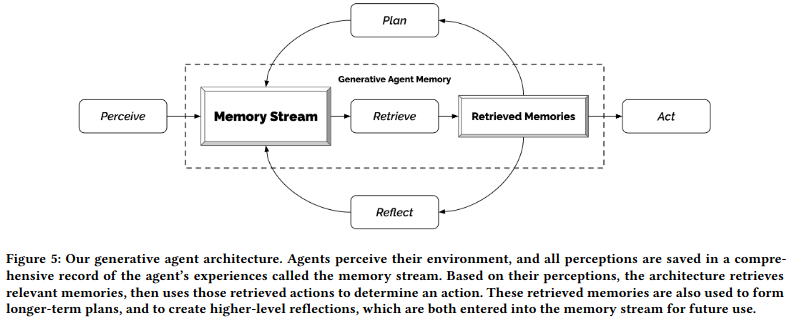
After retrieving history items from the database, the LLM is used to establish the importance of the item with a prompt like:
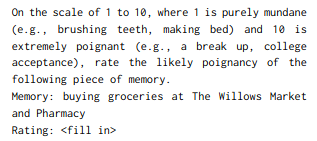
These items are then ranked by recency (how recent was the item), importance (from the LLM), and relevance (to the current situation), and then the top-ranking items are included in the next prompt to the LLM.
Next, the database and LLM are used in a process called “Reflection”, in which the 100 most recent items in the agent’s memory stream are presented to the LLM, which is asked to identify the most important insights with a prompt like the following.

This information is then assembled into a prompt to the LLM that is used to generate a prompt which supplies a description of the agent:

followed by a prompt asking the LLM what is its most likely action:

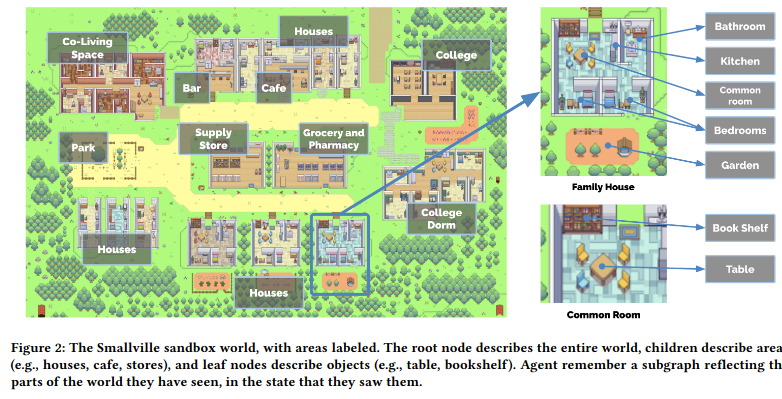
This process is followed by each of 25 independent autonomous agents which are instantiated in a sandbox world called “Smallville” (none of the agents are Clark Kent or Lana Lang).
The agents then go about their lives, move, meet and converse, and interact with one another and external information supplied by the person running the simulation. Here is the diffusion of information within the simulation that resulted from an external input saying that one agent wanted to plan a Valentine’s Day party.
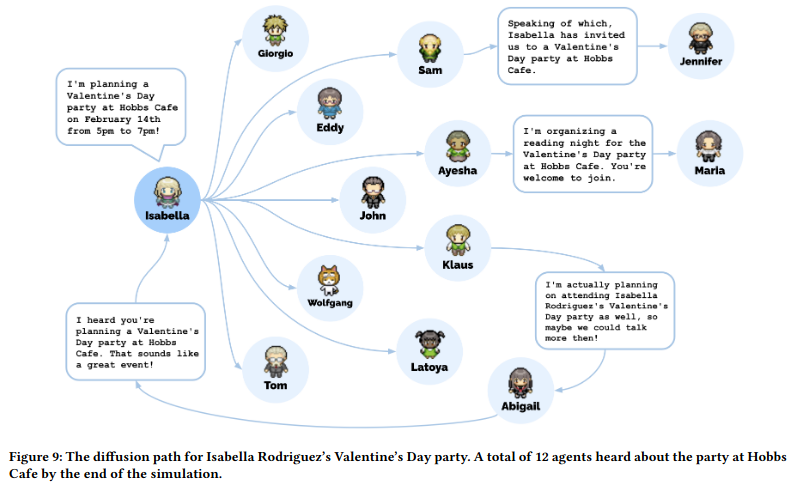
The results are simply stunning. We’ve heard large language models dismissed as “fancy text completion engines” having no semantic understanding of the text they are assembling from their training materials, and certainly no sense of agency or evidence of consciousness. These are conclusions drawn from the LLMs lacking the ability to learn from their interactions and the absence of long term memory or knowledge of the real world environment in which they are interacting. Nonetheless, many of us have been stunned by some of the accomplishments of these models, which seem to exhibit emergent behaviours not previously seen before the training corpora reached the sizes achieved in 2022. It’s been enough to make this long-term sceptic about all things artificial intelligence begin to wonder whether, while LLMs are not the whole answer to what’s going on in the human brain, they may be approaching the capability of one component of human cognition. This experiment uses an LLM as such a component, providing long term memory, prioritisation and reflection on memorised information, and planning and execution of actions based upon each agent’s situation as other components. And the results look a lot like the ways conscious humans react when going through their lives and interacting with one another.
Philip Anderson famously said, “More is different.” Perhaps simply putting together components made possible by the “extravagant computing” resources that have only become available in the Roaring Twenties, we will discover that there’s nothing magical or woo-woo about general intelligence and consciousness, but that it (or something we cannot distinguish from it) emerges when computation and storage capacity scales to a certain size. Moore is different.
You can watch a pre-computed demonstration of this simulation at the “Generative Agents arXiv Demo” Web site. As the simulation replay runs, click on the avatars of the agents in the box at the bottom to display its current state, and then click “State Details” to see a dump of the database information about this agent from which prompts to the LLM are assembled. This experiment was run using ChatGPT with the GPT 3.5-turbo model; GPT-4 was not generally available when the work was done.