OpenAI has just released, under the MIT open source license, a speaker-independent speech recognition system called Whisper, which they say “approaches human level robustness and accuracy on English speech recognition”:
Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. We show that the use of such a large and diverse dataset leads to improved robustness to accents, background noise and technical language. Moreover, it enables transcription in multiple languages, as well as translation from those languages into English. We are open-sourcing models and inference code to serve as a foundation for building useful applications and for further research on robust speech processing.
The Whisper architecture is a simple end-to-end approach, implemented as an encoder-decoder Transformer. Input audio is split into 30-second chunks, converted into a log-Mel spectrogram, and then passed into an encoder. A decoder is trained to predict the corresponding text caption, intermixed with special tokens that direct the single model to perform tasks such as language identification, phrase-level timestamps, multilingual speech transcription, and to-English speech translation.
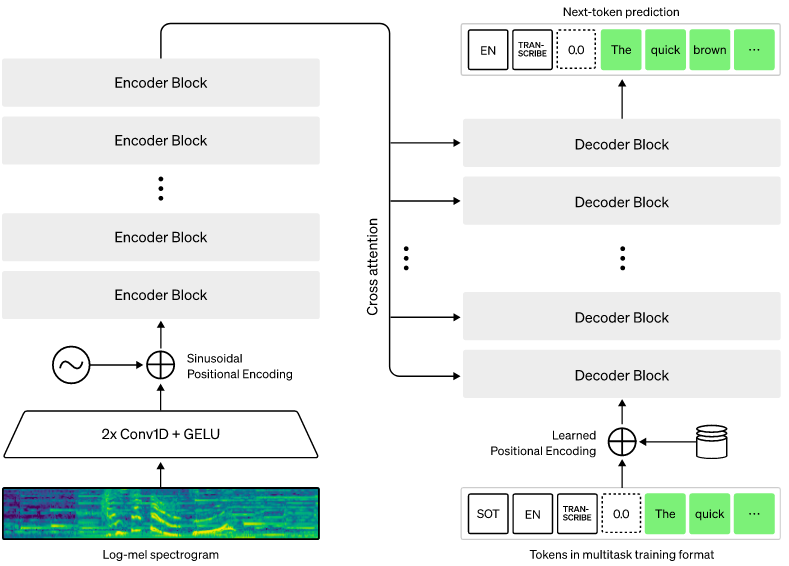
Here is the paper describing the technique and assessing its performance, “Robust Speech Recognition via Large-Scale Weak Supervision” [PDF]. Abstract:
We study the capabilities of speech processing systems trained simply to predict large amounts of transcripts of audio on the internet. When scaled to 680,000 hours of multilingual and multitask supervision, the resulting models generalize well to standard benchmarks and are often competitive with prior fully supervised results but in a zero-shot transfer setting without the need for any fine-tuning. When compared to humans, the models approach their accuracy and robustness. We are releasing models and inference code to serve as a foundation for further work on robust speech processing.
Complete source code and models, ranging in size from 39 Mb to 1.55 Gb, are posted on GitHub for your downloading pleasure. The largest model, built using the multilingual training set, performs as follows on various languages, ranked by Word Error Rate (WER) expressed as a percentage: lower is better.

Speech recognition may be performed from the command line or by function calls within a Python program. For example, to translate speech in Japanese to English text:
whisper japanese.wav --language Japanese --task translate