Google Research has announced “Parti”, for “Pathways Autoregressive Text-to-Image”, another entry in the artificial intelligence text to image synthesis sweepstakes. Unlike OpenAI’s DALL-E 2 and Google’s own Imagen, which are based upon diffusion models, Parti uses autoregression, described as follows.
Parti treats text-to-image generation as a sequence-to-sequence modeling problem, analogous to machine translation – this allows it to benefit from advances in large language models, especially capabilities that are unlocked by scaling data and model sizes. In this case, the target outputs are sequences of image tokens instead of text tokens in another language. Parti uses the powerful image tokenizer, ViT-VQGAN, to encode images as sequences of discrete tokens, and takes advantage of its ability to reconstruct such image token sequences as high quality, visually diverse images.
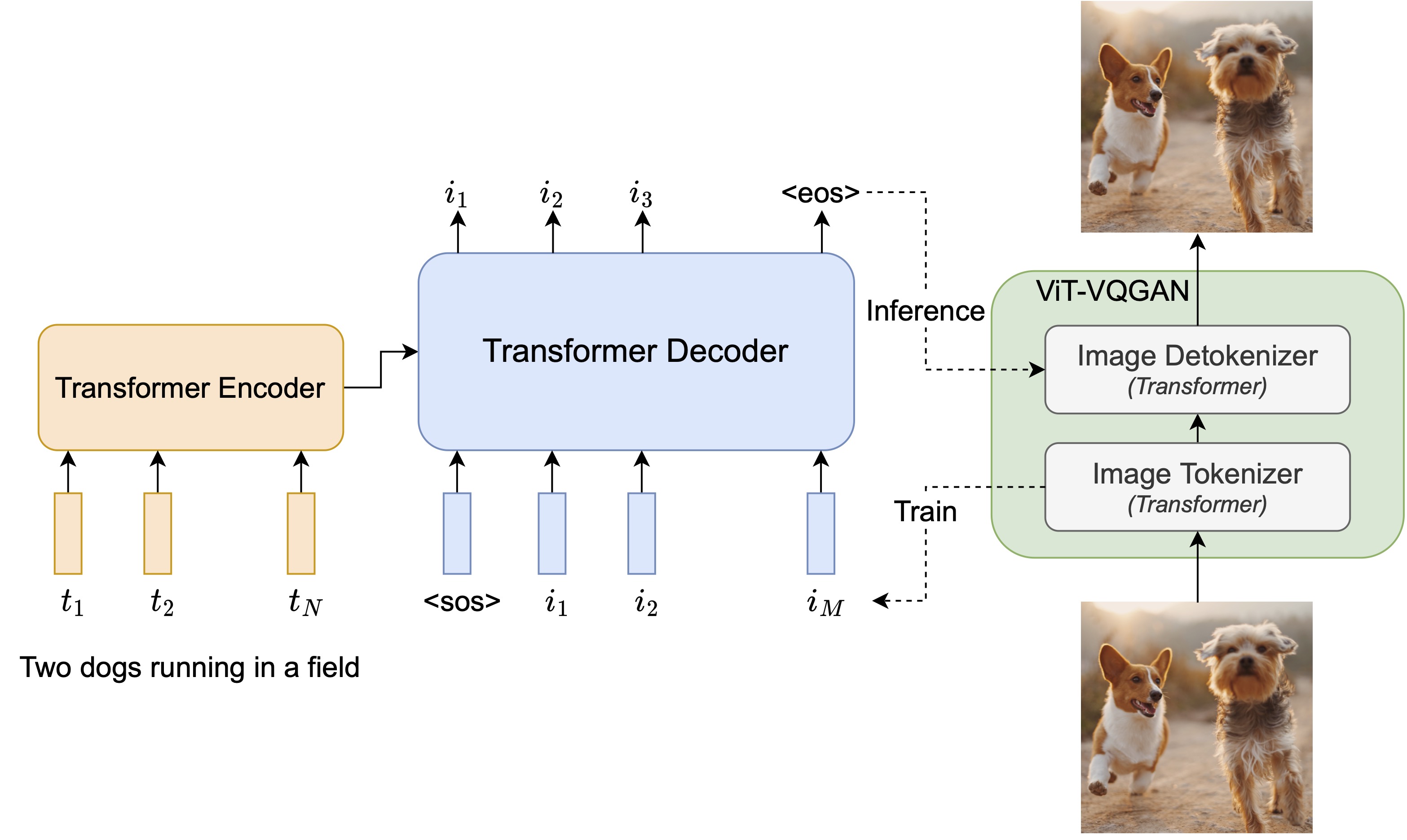
Here is the research paper describing the work, “Scaling Autoregressive Models for Content-Rich Text-to-Image Generation”.
Parti has been trained with four scales of models, ranging from 350 million to 20 billion parameters. The 20 billion parameter model appears to have cracked the barrier of reproducing text and displays a striking level of world knowledge. Here is the result of the prompt:
A portrait photo of a kangaroo wearing an orange hoodie and blue sunglasses standing on the grass in front of the Sydney Opera House holding a sign on the chest that says Welcome Friends!
rendered at four parameter scales of the model.

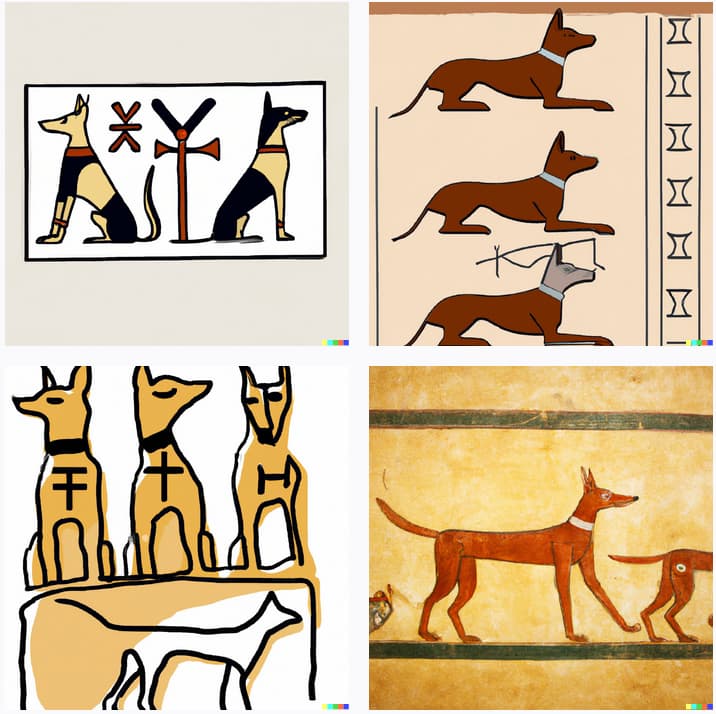
“A photo of an Athenian vase with a painting of pangolins playing basketball in the style of Egyptian hieroglyphics.”

See the Parti Gallery for many more examples.
“A photo of a frog reading the newspaper named “Toaday” written on it. There is a frog printed on the newspaper too.”

“A solitary figure shrouded in mists peers up from the cobble stone street at the imposing and dark gothic buildings surrounding it. an old-fashioned lamp shines nearby. oil painting.”

So, when can you try it? Don’t hold your breath. In a section of the Parti Web site titled “Responsibility and broader impact”, they state:
As we discuss at greater length in the paper, text-to-image models introduce many opportunities and risks, with potential impact on bias and safety, visual communication, disinformation, and creativity and art. Similar to Imagen, we recognize there is a risk that Parti may encode harmful stereotypes and representations. Some potential risks relate to the way in which the models are themselves developed, and this is especially true for the training data. Current models like Parti are trained on large, often noisy, image-text datasets that are known to contain biases regarding people of different backgrounds. This leads such models, including Parti, to produce stereotypical representations of, for example, people described as lawyers, flight attendants, homemakers, and so on, and to reflect Western biases for events such as weddings. This presents particular problems for people whose backgrounds and interests are not well represented in the data and the model, especially if such models are applied to uses such as visual communication, e.g. to help low-literacy social groups. Models which produce photorealistic outputs, especially of people, pose additional risks and concerns around the creation of deepfakes. This creates risks with respect to the possible propagation of visually-oriented misinformation, and for individuals and entities whose likenesses are included or referenced.
and then announce:
For these reasons, we have decided not to release our Parti models, code, or data for public use without further safeguards in place. In the meantime, we provide a Parti watermark on all images that we release. We will focus on following this work with further careful model bias measurement and mitigation strategies, such as prompt filtering, output filtering, and model recalibration. We believe it may be possible to use text-to-image generation models to understand biases in large image-text datasets at scale, by explicitly probing them for a suite of known bias types, and potentially uncovering other forms of hidden bias. We also plan to coordinate with artists to adapt high-performing text-to-image generation models’ capabilities to their work. This is especially important given the intense interest among many research groups, and the rapid development of models and data to train them. Ideally, we hope these models will augment human creativity and productivity, not replace it, so that we can all enjoy a world filled with new, varied, and responsible aesthetic visual experiences.
Or, in other words, we are so afraid of the corpus of information about the real world that has been digested to train our artificial intelligence, including “hate facts” which may not be spoken or even thought in Silicon Valley, that we have decided to restrict access to it to certified woke members of the Inner Parti. Admire the pretty pictures, prole.