SemiAnalysis has obtained and published an internal memo from a Google researcher titled “We Have No Moat, And Neither Does OpenAI”, about which they state:
The text below is a very recent leaked document, which was shared by an anonymous individual on a public Discord server who has granted permission for its republication. It originates from a researcher within Google. We have verified its authenticity. The only modifications are formatting and removing links to internal web pages. The document is only the opinion of a Google employee, not the entire firm. We do not agree with what is written below, nor do other researchers we asked, but we will publish our opinions on this in a separate piece for subscribers. We simply are a vessel to share this document which raises some very interesting points.
The memo argues that Google and OpenAI are losing the race toward artificial general intelligence (AGI/AI) to open source projects, and that (my phrasing), developments on the open source AI front have accelerated in the last two months at a rate reminiscent of the run-up to a Singularity.
We’ve done a lot of looking over our shoulders at OpenAI. Who will cross the next milestone? What will the next move be?
But the uncomfortable truth is, we aren’t positioned to win this arms race and neither is OpenAI . While we’ve been squabbling, a third faction has been quietly eating our lunch.
I’m talking, of course, about open source. Plainly put, they are lapping us. Things we consider “major open problems” are solved and in people’s hands today. Just to name a few:
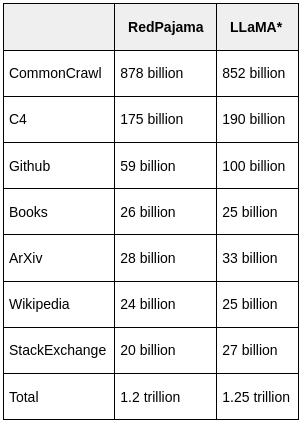
While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months. This has profound implications for us:…
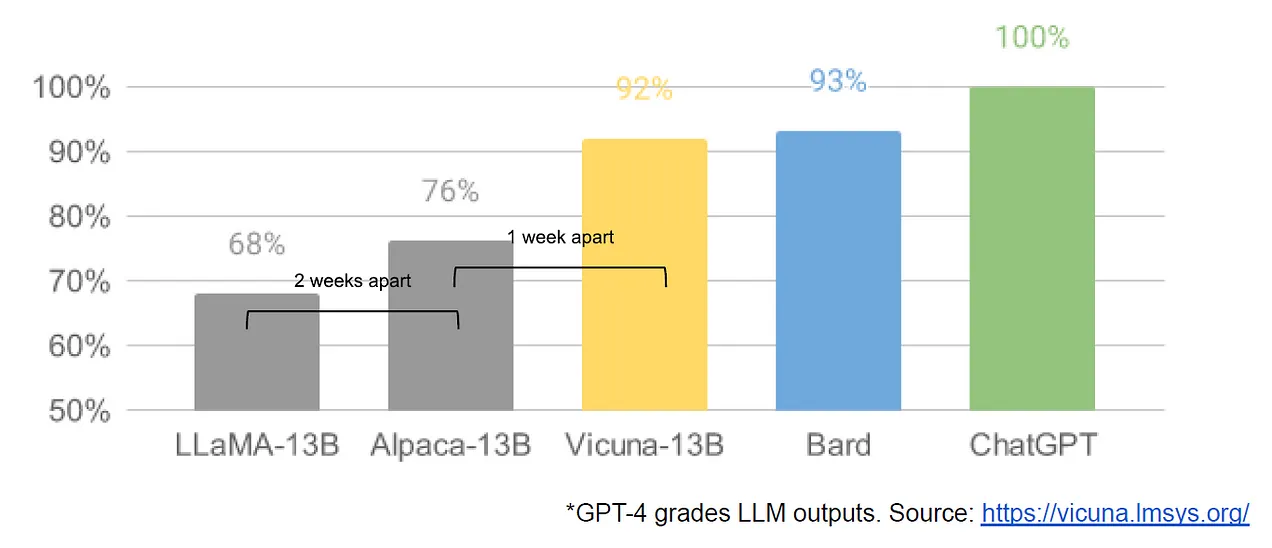
Here is a chart illustrating the rate at which open source is catching up to the big proprietary models.
In many ways, this shouldn’t be a surprise to anyone. The current renaissance in open source LLMs comes hot on the heels of a renaissance in image generation. The similarities are not lost on the community, with many calling this the “Stable Diffusion moment” for LLMs.
In both cases, low-cost public involvement was enabled by a vastly cheaper mechanism for fine tuning called low rank adaptation, or LoRA, combined with a significant breakthrough in scale (latent diffusion for image synthesis, Chinchilla for LLMs). In both cases, access to a sufficiently high-quality model kicked off a flurry of ideas and iteration from individuals and institutions around the world. In both cases, this quickly outpaced the large players.
These contributions were pivotal in the image generation space, setting Stable Diffusion on a different path from Dall-E. Having an open model led to product integrations, marketplaces, user interfaces, and innovations that didn’t happen for Dall-E.
The effect was palpable: rapid domination in terms of cultural impact vs the OpenAI solution, which became increasingly irrelevant. Whether the same thing will happen for LLMs remains to be seen, but the broad structural elements are the same.
It’s out there, it’s replicating and building on itself, and there’s nothing that can be done to control it.
Individuals are not constrained by licenses to the same degree as corporations
Much of this innovation is happening on top of the leaked model weights from Meta. While this will inevitably change as truly open models get better, the point is that they don’t have to wait. The legal cover afforded by “personal use” and the impracticality of prosecuting individuals means that individuals are getting access to these technologies while they are hot.
“An entire planet’s worth of free labour…”
Paradoxically, the one clear winner in all of this is Meta. Because the leaked model was theirs, they have effectively garnered an entire planet’s worth of free labor. Since most open source innovation is happening on top of their architecture, there is nothing stopping them from directly incorporating it into their products.
Here is the timeline of recent events in the explosive growth of open source AI. Each of these is explained in a paragraph in the memo.
- Feb 24, 2023 - LLaMA is Launched
- March 3, 2023 - The Inevitable Happens (LLaMA leaked to the public)
- March 12, 2023 - Language models on a Toaster (LLaMA running on Raspberry Pi)
- March 13, 2023 - Fine Tuning on a Laptop (Stanford releases Alpaca, with tuning on a consumer GPU)
- March 18, 2023 - Now It’s Fast - Tuning demonstrated on a MacBook with no GPU
- March 19, 2023 - A 13B model achieves “parity” with Bard (Vicuna trains model woth GPT-4 for US$ 300)
- March 25, 2023 - Choose Your Own Model (Nomic’s GPT4All integrates model and ecosystem)
- March 28, 2023 - Open Source GPT-3 (Cerebras trains GPT-3 from scratch)
- March 28, 2023 - Multimodal Training in One Hour (LLaMA-Adapter tunes in one hour, with 1.2 million parameters)
- April 3, 2023 - Real Humans Can’t Tell the Difference Between a 13B Open Model and ChatGPT (Berkeley launches Koala, trained entirely with free data for a training cost of US$ 100)
- April 15, 2023 - Open Source RLHF at ChatGPT Levels (Open Assistant launches a model and dataset for Reinforcement Learning from Human Feedback [RLHF]. Alignment is now in the wild.)