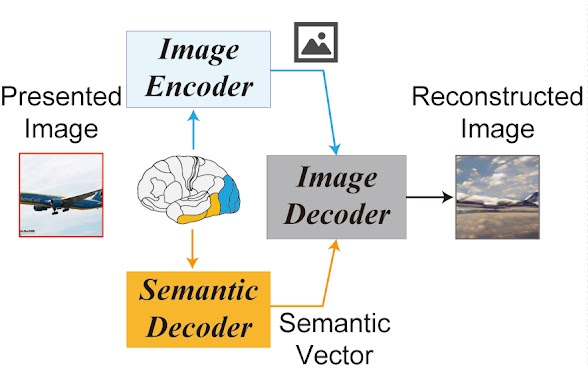
In a mind-boggling (or is it mind-reading?) paper posted on bioRχiv, two researchers from the Osaka University Graduate School of Frontier Biosciences in Japan, “High-resolution image reconstruction with latent diffusion models from human brain activity”, report that they have been able to reconstruct images from human brain activity detected by functional magnetic resonance imaging (fMRI), using the brain scan information to drive the Stable Diffusion latent diffusion model image synthesis system.
The results are stunning.

Here is the abstract from the paper.
Reconstructing visual experiences from human brain activity offers a unique way to understand how the brain represents the world, and to interpret the connection between computer vision models and our visual system. While deep generative models have recently been employed for this task, reconstructing realistic images with high semantic fidelity is still a challenging problem. Here, we propose a new method based on a diffusion model (DM) to reconstruct images from human brain activity obtained via functional magnetic resonance imaging (fMRI). More specifically, we rely on a latent diffusion model (LDM) termed Stable Diffusion. This model reduces the computational cost of DMs, while preserving their high generative performance. We also characterize the inner mechanisms of the LDM by studying how its different components (such as the latent vector of image Z, conditioning inputs C, and different elements of the denoising U-Net) relate to distinct brain functions. We show that our proposed method can reconstruct high-resolution images with high fidelity in straight-forward fashion, without the need for any additional training and fine-tuning of complex deep-learning models. We also provide a quantitative interpretation of different LDM components from a neuroscientific perspective. Overall, our study proposes a promising method for reconstructing images from human brain activity, and provides a new framework for understanding DMs.
The project’s Web site provides additional material and illustrations describing the process. The technique requires no special training of the neural networks for a specific subject. Here is an example of presenting an image to four different subjects and then reading their minds and reconstructing the image.

Based upon the wonders we’ve seen in the domain of artificial intelligence in just the last year, it is increasingly difficult to be stunned by the results being reported, but this does the trick for me. This is something I didn’t think we’d see before 2050, if then.
I wonder if it works on images generated internally by the brain and perceived during dreams.