This was a conversation about the state of large language models (LLMs), why they have become so effective in generating human-like text and solving other problems such as language translation, summarisation, and classification, and how it is that such a simple process (choosing among the most probable words to continue a prompt) can have such unreasonably impressive results. It wasn’t about how to extend the capabilities of existing models or design approaches (for example, recurrent neural networks to provide a form of read-write memory within the network itself, or systems that implement inductive reasoning based upon lossless compression of source data, which have been discussed here in a number of other posts). These are topics about which neither I nor Rudy know very much, so a conversation about them wouldn’t be enlightening for readers.
One possible direction in generalising LLMs and broadening their utility is that suggested by Andrej Karpathy in a talk at the AI Security Summit in November, 2022 titled “Intro to LLMs” (link is to a PDF of slides from the talk, below is a video posted on 2023-11-23 of a recreation of the talk from the slides).
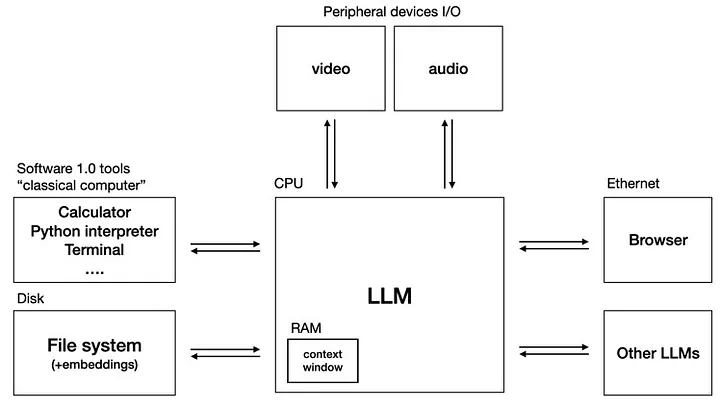
In the talk, Karpathy spoke of LLMs as a kernel component of a new emerging kind of operating system. Here is how he described it on 𝕏 on 2023-09-28:

Here, from the talk, is how this “LLM OS” might be structured.
In other words, the LLM is a service provided by an operating system to facilitate interaction in natural language, interface with video and audio, generation and transformation of computer programs, etc. just as an operating system today is expected to contain services for mapipulating files, scheduling processes, communicating over networks, and providing access to peripheral devices. As LLMs migrate from cloud services to open source locally-hosted software components (I posted here on 2023-12-13 on tools that make an LLM accessible via Linux shell scripts), they will become less magic and more a mundane software service one uses when appropriate just like a SQL database back-end.
Seen this way, we shouldn’t expect an LLM to “grow up” into an artificial general intelligence (AGI) system, but rather act as the “speech centre” of a larger and more complex system that contains other modules for planning, homeostasis, locomotion, etc. just as the brain localises those functions in different areas.
Toward this end, here is a rant from Karpathy on 2023-12-09 on 𝕏 about the “hallucination problem” in LLMs, which I present here as text for easier quoting.
On the “hallucination problem”
I always struggle a bit with I’m asked about the “hallucination problem” in LLMs. Because, in some sense, hallucination is all LLMs do. They are dream machines.
We direct their dreams with prompts. The prompts start the dream, and based on the LLM’s hazy recollection of its training documents, most of the time the result goes someplace useful.
It’s only when the dreams go into deemed factually incorrect territory that we label it a “hallucination”. It looks like a bug, but it’s just the LLM doing what it always does.
At the other end of the extreme consider a search engine. It takes the prompt and just returns one of the most similar “training documents” it has in its database, verbatim. You could say that this search engine has a “creativity problem” - it will never respond with something new. An LLM is 100% dreaming and has the hallucination problem. A search engine is 0% dreaming and has the creativity problem.
All that said, I realize that what people actually mean is they don’t want an LLM Assistant (a product like ChatGPT etc.) to hallucinate. An LLM Assistant is a lot more complex system than just the LLM itself, even if one is at the heart of it. There are many ways to mitigate hallcuinations in these systems - using Retrieval Augmented Generation (RAG) to more strongly anchor the dreams in real data through in-context learning is maybe the most common one. Disagreements between multiple samples, reflection, verification chains. Decoding uncertainty from activations. Tool use. All an active and very interesting areas of research.
TLDR I know I’m being super pedantic but the LLM has no “hallucination problem”. Hallucination is not a bug, it is LLM’s greatest feature. The LLM Assistant has a hallucination problem, and we should fix it.
</rant> Okay I feel much better now :).