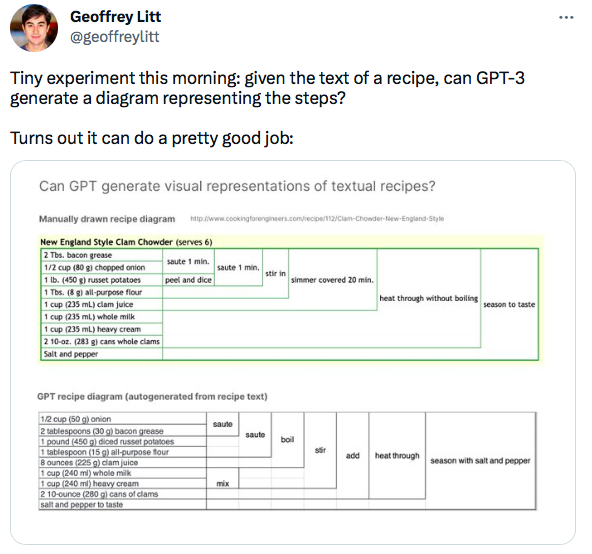
The size of the model does help, but the most important component of the recent breakthroughs in AI are the loading of relevant text into context, as well as the size of the model. Here’s how this context loading (or ‘stuffing the prompt’) works from a recent Manifold1 podcast by Steve Hsu:
Sahil Lavingia: Exactly. And so, I just, I felt like, you know, they’re books are still great. I, you know, and I still read them, and people should continue to write them, but maybe there are different kinds of formats that, you know, we can explore. And I felt like one of those, and I saw this. I forget exactly how I saw it, but I, I sort of realized like, oh wait, like, you know, one issue with GPT-3 is that you can’t, it’s not focused, right?
It’s like, it’s just like you can’t ask questions like a book, or something like that. You can ask if it happens, have read the book as part of, you know, it’s training maybe, but, but, but not really. And so, what I discovered was this concept of embeddings, which blew my mind. which was just basically this idea that pretty simply I could take 50,000 words from my book and effectively find the most relevant 500 words.
And that means that that’s enough that I can just put those words directly in the prompt and effectively, you know, all of the code is, all the sort of conditional logic is just actually part. Prompt window that the user doesn’t actually see. But it basically says, you know, Sahil is, you know, the founder of GumRoad, he wrote a book, this is a question, answer It, right?
That sort of thing. but what you can do with embeddings is you can actually say, by the way, here’s some context from the book that might be useful. Insert all of that in the context and then answer, you know, sort of have that, have the AI complete that prompt. And when I realized that insight, I was like, wait a second, this is an amazing use case for AI and chat.
This would make chatting about a subject interesting. And, and at that point, this is, you know, before chatting GPT. So now chatting with AI is popular again. But that was a pretty, I think, key insight I had, which was like, there’s a better format for like, question answer. The question answer is, you know, really AIs become really good for question answers.
People don’t know this yet. And so, I’m going to build a chat UI. you know, for my book basically to, to be able to talk to my book. and so, I built that into askmybook.com. It’s, you know, like maybe 200, 300 lines of Python. it sort of takes the, the, the, the PDF of my manuscript, turns it into a CSV file of pages, and then takes that page’s CSV file, you know, creates embeddings on it using open AI’s API, and then uses those embeddings to, you know, stuff the prompt.
And so, it’s effectively like, sort of two, two things happening. But yeah, it’s, it’s, it’s kind of magical. It’s kind of magical when you realize like, oh wow. It’s just like, it’s a very simple thing, right? but it, it, it feels like you’re sort of standing on the shoulders of giants, you know? It’s like I built Google search without having to build Google search, you know, just by building the, the, the box, the input.
This was October 2022. So it’s theoretically possible that OpenAI took that and did their own context loading / prompt stuffing, and launch ChatGPT.