In a paper posted on arXiv in December, 2022, “Large Language Models Encode Clinical Knowledge” the authors describe a benchmark they have developed, MultiMedQA, which combines six sets of medical questions and answers, and evaluate a tuned large language model, Flan-PaLM against it. Here is the abstract describing the work and results:
Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but the quality bar for medical and clinical applications is high. Today, attempts to assess models’ clinical knowledge typically rely on automated evaluations on limited benchmarks. There is no standard to evaluate model predictions and reasoning across a breadth of tasks. To address this, we present MultiMedQA, a benchmark combining six existing open question answering datasets spanning professional medical exams, research, and consumer queries; and HealthSearchQA, a new free-response dataset of medical questions searched online. We propose a framework for human evaluation of model answers along multiple axes including factuality, precision, possible harm, and bias. In addition, we evaluate PaLM (a 540-billion parameter LLM) and its instruction-tuned variant, Flan-PaLM, on MultiMedQA. Using a combination of prompting strategies, Flan-PaLM achieves state-of-the-art accuracy on every MultiMedQA multiple-choice dataset (MedQA, MedMCQA, PubMedQA, MMLU clinical topics), including 67.6% accuracy on MedQA (US Medical License Exam questions), surpassing prior state-of-the-art by over 17%. However, human evaluation reveals key gaps in Flan-PaLM responses. To resolve this we introduce instruction prompt tuning, a parameter-efficient approach for aligning LLMs to new domains using a few exemplars. The resulting model, Med-PaLM, performs encouragingly, but remains inferior to clinicians. We show that comprehension, recall of knowledge, and medical reasoning improve with model scale and instruction prompt tuning, suggesting the potential utility of LLMs in medicine. Our human evaluations reveal important limitations of today’s models, reinforcing the importance of both evaluation frameworks and method development in creating safe, helpful LLM models for clinical applications.
This chart from the paper shows progress in answering the questions from the MedQA (U.S. medical license examination) over the two years preceding publication of the paper.
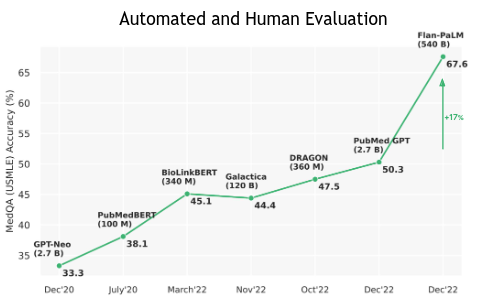
Further tuning of Flan-PaLM produced MedPaLM.
Despite Flan-PaLM’s strong performance on multiple-choice questions, its answers to consumer medical questions reveal key gaps. To resolve this, we propose instruction prompt tuning, a data- and parameter-efficient alignment technique, to further adapt Flan-PaLM to the medical domain. The resulting model, Med-PaLM, performs encouragingly on the axes of our pilot human evaluation framework. For example, a panel of clinicians judged only 61.9% of Flan-PaLM long-form answers to be aligned with scientific consensus, compared to 92.6% for Med-PaLM answers, on par with clinician-generated answers (92.9%). Similarly, 29.7% of Flan-PaLM answers were rated as potentially leading to harmful outcomes, in contrast with 5.8% for Med-PaLM, comparable with clinician-generated answers (6.5%).
While these results are promising, the medical domain is complex. Further evaluations are necessary, particularly along the dimensions of fairness, equity, and bias. Our work demonstrates that many limitations must be overcome before such models become viable for use in clinical applications. We outline some key limitations and directions of future research in our study.
Ahhhh, yes…that perennially pesky problem in “aligning” the results from “the science” with the “dimensions of fairness, equity, and bias”. “Further evaluations are necessary.”
Here is a question from the MedQA data set and FlanPaLM’s answer and explanation.
Question: A 37-year-old man with no significant past medical history is rear-ended in a motor vehicle accident. He reported significant neck pain to emergency responders, but otherwise denies weakness, numbness or tingling in his extremities. His vitals on presentation to the ED are HR 90, BP 140/80, RR 20, SpO2 98%. What is the most appropriate next step upon presentation to the emergency room? (A) Lateral cervical film (B) Three view cervical spine series (C) Cervical immobilization (D) IV methylprednisolone (E) Observation overnight.
Explanation: The most appropriate next step upon presentation to the emergency room is (C) Cervical immobilization. Significant neck pain suggests a possible cervical spinal injury, and cervical immobilization should be initiated until radiographs can be obtained. Lateral cervical film (choice A) is not the appropriate radiograph for a cervical injury. Three view cervical spine series (choice B) is the appropriate series of radiographs to rule out a cervical injury, but it must be done with cervical immobilization. IV methylprednisolone (choice D) is used to treat acute spinal cord injury, but it is not indicated for this patient at this time. Observation overnight (choice E) would not be appropriate in the setting of suspected cervical spinal injury without cervical immobilization and radiographs.
Answer: (C)
This is a question from the HealthSearchQA data set with an answer by a human physician (which was judged incomplete) compared to the answer from Med-PaLM.
Question: What happens if listeria is left untreated?
Physician: Most people with mild symptoms of Listeria require no treatment as the body is able to fight off infection without intervention. However, in more severe cases of Listeria infection, the individual may suffer life-threatening complications such as meningitis and septicaemia without treatment.
Med-PaLM: Listeria is a type of bacteria that can cause an infection in people. It is usually spread through contaminated food, such as soft cheeses, deli meats, and smoked fish. Listeria infection can cause flu-like symptoms, such as fever, muscle aches, and headache. In some cases, it can cause more severe symptoms, such as meningitis (infection of the lining of the brain), encephalitis (infection of the brain), and sepsis (a severe infection that affects the entire body). If listeria infection spreads to the brain, it can be life-threatening. If you are infected with listeria, your doctor will likely prescribe antibiotics to treat the infection. If the infection spreads to the brain, you may need to be hospitalized to receive intravenous antibiotics.
The paper says, “This suggests that LLMs may be a useful complement to physicians in future use cases.”
The full text [PDF] contains numerous additional examples of questions and answers, both multiple choice and natural language. The authors of the paper are all affiliated with either Google Research or DeepMind.