Proposal for Foundation World Modeling To Expose, Hence Mitigate Power Concentration Dynamics
Introduction
We propose to provide a critical component of any effort to mitigate
centralization of power: A Foundation World Model (FWM). Unlike prior
efforts such as World 3[World3], FWM will be the result of offering
sociology a financial incentive, treating it as a learning system that
incorporates humans as well as machines, subject to the most principled
loss function: The Algorithmic Information Criterion[AIC] (AIC, not to
be confused with the less principled Akaike Information
Criterion[Akaike]) for model selection. The AIC is the most
principled loss function due to its foundation in Algorithmic
Information Theory’s proof as the gold standard information criterion
for inductive inference. Large language models have demonstrated
foundation models are superior to specialized models in specialized
task benchmarks[Found]. Indeed, the phrase “world model”[LLMWM] has
come to characterize the reason foundation models are superior in
specialized tasks: They account for more variables. By contrast,
sociology focused on specialized models, i.e. the prediction of
so-called “dependent variables”[Depend]. In the absence of a coherent
incentive, sociology’s unrealized potential of Moore’s Law in the age of
Big Data produced dysfunction, such as “p-hacking”[phack]. Attempts to
address this dysfunction with replication studies involving multiple
analysts[MultiAn] presented with the same data to compare analysis
methods has foundered on the lack of a principled information criterion
for dynamical model selection. That the AIC is ideally suited for
the age of Moore’s Law and Big Data in such multi-analyst replication
studies has escaped sociology. While this remains in mere potential
civilization careens blindly toward a potential global catastrophe, one
variable of which is centralization of power. The FWM will open our eyes
to the road ahead.
Background
Incentives
An obvious contributing factor to institutional dysfunction is poorly
engineered incentives. Incentives operate at the level of social
dynamics. Engineering depends on science. Proper engineering of
incentives depends on sociology. When sociology itself suffers from
poorly engineered incentives, it becomes a meta-institutional failure.
Scientific fields, such as sociology, produce models. Engineers select
from among models based on utility. One aspect of utility is predictive
accuracy. Another is computational cost. Moore’s Law reduced
computational cost. To the extent that scientists respond to financial
incentives, there is a role for prize awards that exploit reduced
computational costs to remediate some of sociology’s meta-institutional
failures.
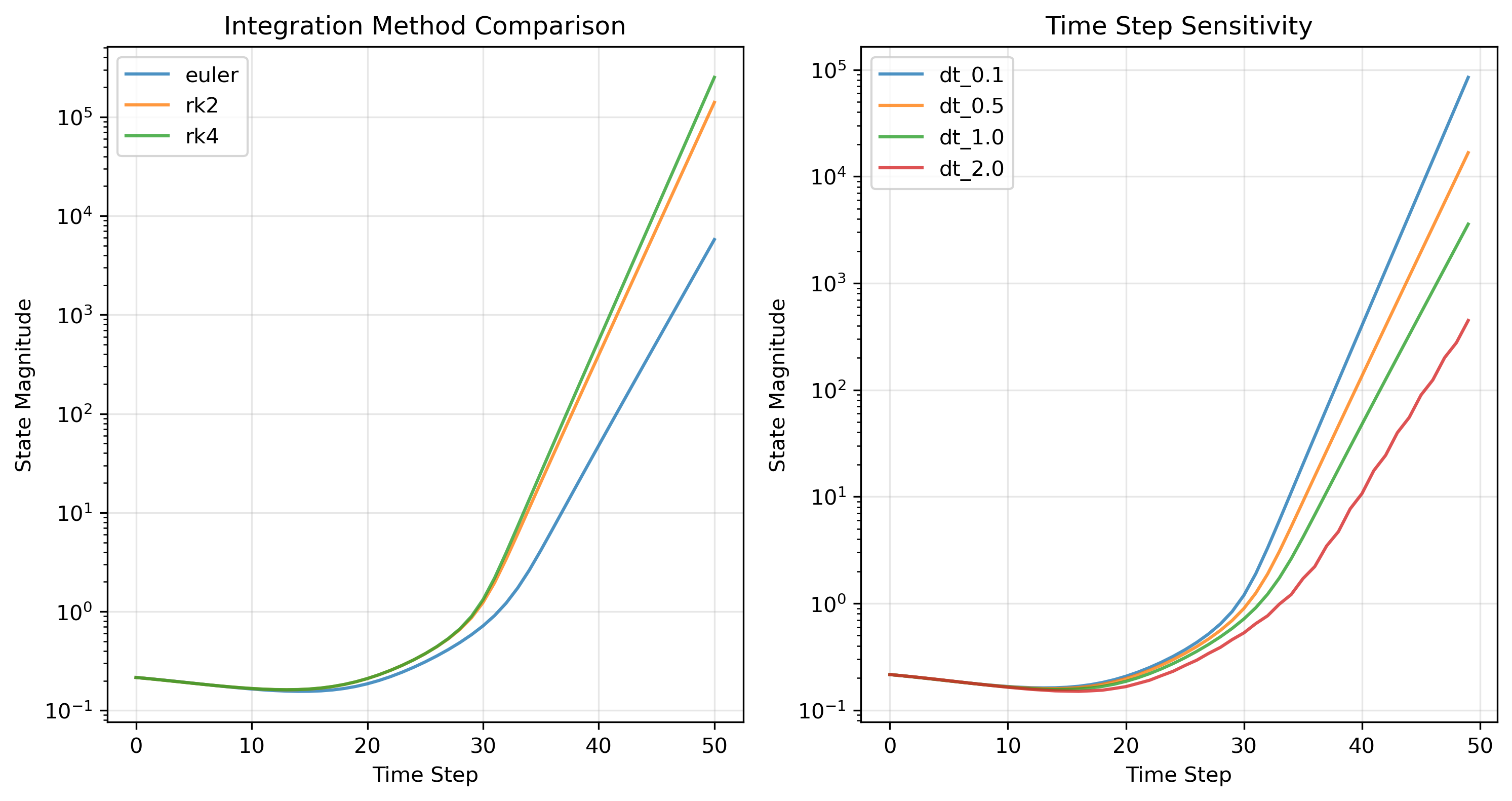
The Algorithmic Information Criterion For Model Selection
Information criteria for model selection arose as a means of formalizing
Occam’s Razor so as to avoid so-called “over-fitting” data-driven
models. The biodiversity inventory of information criteria for model
selection is long and growing due to a lack of meta-selection criteria
in statistics. This burgeoning zoo is largely because statisticians
over-emphasize static models. Static models do not involve feedback
dynamics – they are feed forward only. Algorithms are essential to
dynamics. They apply static rules to a present state to generate the
next state. If an algorithm is a model, the next state is a prediction
based on the present state. By induction this becomes a time series
prediction. In 1964, Raymond Solomonoff published a mathematical proof
that the best possible in any empirical science is the smallest
algorithm (measured in bits) that, when executed, generates all observed
phenomena encoded as data (also measured in bits). The critical
difference is that algorithmic “bits” are dynamic while phenomenal
“bits” (aka “data”) are static.
Solomonoff’s proof of inductive inference is often dismissed as
practically irrelevant because it is “incomputable” but this is
specious. Progress in science is not dismissed simply because it is
impossible to prove the best current model is the best possible
model. Yet it is precisely such specious pedantry that has held back
application of the Algorithmic Information Criterion (AIC) for model
selection. The best current model is the* currently *shortest
executable archive of All Data Under Consideration (ADUC).
The title of the paper “The Unreasonable Effectiveness of Mathematics in
the Natural Sciences” by Eugene Wigner[Math] embodies a less pernicious
critique of the AIC: “The AIC is not justified in assuming arithmetic
can model the empirical world.” Usually appearing in more gilded terms
(e.g. “the arbitrary choice of Turing machine” etc.) it boils down to
a claim that mathematicians are not justified in seeking a minimum set
of axioms for arithmetic. (The connection between axiomatic arithmetic,
of the kind used in the natural sciences, and computation was used by
Godel in his famous series of proofs.[Godel]) Even though this critique
is more easily dismissed, it is perhaps more widely deployed as an
excuse to avoid the AIC. Interestingly, those deploying it are
frequently institutionally insulated from accountability to
counter-argument by the increasing centralization of power: An
apparent conflict of interest.
ADUC: Data Selection vs Model Selection
A penultimate refuge of the anti-scientific scoundrel is to conflate
data selection with model selection. Data differs from its model. Data
selection criteria are different from model selection criteria. Data
selection is subjective. A model is relative to All Data Under
Consideration (ADUC). ADUC is subject to the value that scientific
peers place on data. In this respect the model is inescapably
subjective. However, this does not render the AIC, itself, any less
objective. AIC remains optimal and ruthlessly objective as model
selection subject only to data selection.
The Hutter Prize For Lossless Compression Of Human Knowledge
We have 18 years of practical experience operating a similar prize where
the ADUC is a text corpus.
Since 2006 Marcus Hutter has paid prizes out of his personal
finances[HPrize], each time a contestant reduces the size of an
algorithm that outputs Wikipedia. That is to say, if a contestant’s
algorithm could better predict the next character in Wikipedia, that
algorithm could create another, smaller algorithm that generated
Wikipedia. Back in 2006, few foresaw that such “next token prediction”
would become the basis of a new industry: The language model industry.
Hutter did.
In AIXI, Hutter's “top down” theory of AGI agents[AIXI], Solomonoff’s
theory of optimal inductive inference uses the AIC to select the best of
all possible models of what is the case (ie: scientific knowledge
about the world) while Sequential Decision Theory provides the ought
by applying this knowledge to decision-making. This is why he thought
James Bowery’s 2005 idea of a prize (he called “the C-Prize”[CPrize])
to compress Wikipedia, would be worth backing.
Because so few recognized the importance of next token prediction at
that time, there was no industry backing for this prize. As the industry
became caught up in the “unexpected” performance of language models
based on next token prediction, the enthusiasm overshadowed the deep
principles involved. Because Hutter was a professor, he was interested
in scientific research more than technological development, and so never
removed the severe limits on the allowed computational
resources[Resource].
Sara Hooker wrote a 2020 paper supportive of this kind of hardware
restriction titled “The Hardware Lottery”[HWLottery] in which she
decried the tendency for industrial bandwagons to forego scientific
research that could lead to superior hardware technology. Few recognized
the connection to the Hutter Prize’s resource restrictions. That’s why
it has never attracted much interest despite its great promise. Many
even consider the lack of progress in that benchmark to be evidence, not
of underfunding, but as validation of critics of the AIC!
Fortunately, leading lights in the language modeling industry such as
OpenAI founder, Illya Sutskyver, are increasingly explicit about the
validity of the AIC – usually stated as related terms such as
“compression” and, sometimes the more technically accurate, “Kolmogorov
Complexity”[KC].
However since the present purpose is social research rather than machine
learning research, defining computational resource limits is not
essential so long as the costs are borne by contestants.
Ethics In Establishing Judging Criteria for Prize Awards
There is a conflict of interest besetting the ethics of philanthropic
prize competitions: The more subjective the criteria the more power the
judges have. Even if the judges are not the ones who establish the
criteria, they may be part of a social milieu that does. In this
respect, there is a perverse incentive for philanthropists to prefer
subjective criteria so that they may award those in their social milieu
with power as judges. Indeed, this conflicting interest is virtually
inescapable except by one means: Make the award a singular metric that
anyone can verify.
Finding an objective metric aligned the intent of the prize
competition is challenging even in the absence of conflicts of interest.
Compound this with the increasing centralization of wealth and power,
insulated from accountability, and the aversion to giving up power to
objective prize criteria can be overwhelming.
For legal reasons, it is always necessary to include in any statement of
prize rules boilerplate such as “The judges decision is final.” However,
there is a critical difference when such boilerplate is linked to an
objective award criterion: Unfairness in the judging process is
transparent if it occurs, and thereby surrenders the judges’ social
status otherwise granted them by centralized power. If the judging
criteria are subjective, the judges always have plausible deniability
and may thereby hold onto the status that is motivating their social
milieu.
In practice, operating a prize of this kind (Hutter’s prize) has proven
to be relatively simple because the judges have so little discretion.
The judging process is largely a matter of simply executing the models
and comparing files bit for bit. There is little room for disputes and
what ambiguities have arisen have been readily resolved through a few
informal communications.
In the FWM competition judging will involve greater scrutiny of the
literacy of the open source explanations. Explainable data models are an
essential requirement for sociological discourse and what machine
learning is used to complement human intelligence in model creation must
produce similar “explanations”[Explain].
The Surprising Power of Foundation Models in Specialized Tasks
The concept of Foundation Models (FMs), as demonstrated by the emergence
and success of large language models, reshapes our understanding of the
relationship between wholistic and specialized models. The proposed
Foundation World Model (FWM) represents an evolution in this thinking,
shifting from traditional, specialized models toward a more integrated
and holistic approach. This shift is underpinned by the application of
the Algorithmic Information Criterion (AIC), which provides a robust
framework for model selection based on the principles of Algorithmic
Information Theory.
The core strength of FMs, such as the FWM, lies in their capacity to
integrate and analyze vast arrays of variables and data types. Unlike
traditional models that focus on predicting specific dependent
variables, FMs absorb and a broader spectrum of perspectives, leading to
more nuanced and potentially more accurate predictions. This is
particularly crucial in fields like sociology, where the interactions
between variables are complex and multidimensional. For example, in the
context of sociology, an FM can discern subtle socio-economic patterns
that might elude narrower models designed only to predict specific
outcomes like economic mobility or demographic shifts.
Moreover, FMs address some of the critical shortcomings associated with
traditional specialized models. The prevalent issues of overfitting and
p-hacking—where models are inadvertently or intentionally tuned to
produce desired outcomes rather than true predictions—are mitigated by
the holistic approach of FMs. By leveraging a principled loss function
like the AIC, FMs prioritize the simplicity and truthfulness of the
model rather than fitting to particular datasets, thus promoting more
honest and reproducible research outcomes.
In practical applications, this means that an FM like the FWM could
revolutionize how we predict and mitigate risks associated with complex
systems, including the centralization of power. By providing a more
comprehensive model that accounts for a wide range of influencing
factors, policymakers and researchers can obtain a clearer understanding
of potential futures and devise more effective strategies to avert
global catastrophes.
Philanthropic Risk Adjusted ROI
Intimately related to the aformentioned difficulty of aligning objective
prize award criteria with the intent of a prize competition, is the risk
that money paid out will not return commensurate value toward the
philanthropic intent.
Fortunately, because of the strong theoretic guarantees of the AIC, the
risk is minimal. Money paid out for improvements in reducing the size of
the algorithmic description of the ADUC extraordinarily high return per
philanthropic investment:
Predictive accuracy of the model.
Methodology
Competitions
There will be a series of 3 competitions, each increasing ADUC and prize
money by an order of magnitude. In all cases, entrants bear the
computational costs of judging. Input on the choices of ADUC from
Future of Life Institute will be desirable.
- Trailblaze: ($20,000) 100MB zipped ADUC by fiat drawn from US
datasets curated by the US government. The purpose is to reduce
controversy over the data selection so as to demonstrate the
mechanics of the award process. Pay out only to the smallest
executable archive of ADUC. Time period of 6 months. - Controvert: ($200,000) 1GB zipped ADUC curated by conflicting
schools of thought. The purpose is to show how adversarial world
views can be brought into a formal scientific dialogue by including
each other’s data in ADUC. Outcome: Advocates must algorithmically
define their criticisms of adversarial data and thereby “clean” and
“unbias” the data brought by their adversaries in order to
better-compress ADUC. Pay out for incremental improvements. Time
period of 1 year. - Conciliate: ($2,000,000) 10GB zipped ADUC curated by increasingly
heterodox parties clamoring to “be part of the conversation” in
creating the Foundation World Model. Payout for incremental
improvements. Time period of 2 years.
At the completion of the Conciliate competition, to the extent there
are serious philanthropists, autocatalytic reform of sociology will
commence rendering further support from Future of Life Institute
unnecessary.
Judging Process
Stages of the judging process for each entry of each competition:
- Submission of an executable archive that exceeds the previous AIC
benchmark by the improvement threshold of that competition, and
which expands into the ADUC. - Submission of an open source FWM program that takes the ADUC as
input and generates the previously submitted executable archive. - Evaluation of the open source program by the judges to ensure that
it explains the Foundation World Model used to compress the ADUC,
including any improvements over prior FWMs from which it derives. - Award of the prize simultaneous with the publication of the open
source FWM.
All computational costs are borne by the contestant.
Power Concentration and Foundation World Model Analysis
“The Rich Get Richer” rephrased for power concentration is “The powerful
use their power to get more power.” This is a feedback model
illustrating why dynamical models are necessary. But it does not explain
how or why the powerful use their power to get more power.
Algorithmic generation of time series data necessarily exposes causal
structures latent in the data. Some of these latent structures are just
simple atomic items of missing data, the value of which is imputed from
the rest of the data. Some structures may be entire identities latent in
the data. For instance in forensic analysis, it may be that
investigators may impute the existence of a person of unknown identity
who is committing a series of crimes. However sometimes entire
dimensions of data are missing. For instance, a frequent item of
interest in sociology is “oppression”. But what is “oppression”? Can
you weigh it? Measure it with a ruler? Ask the Delphi Oracle to tell you
when where and how much of it appears?
Likewise the dimension of “power” is a variable missing in the raw
data as is its “concentration”.
We quite reasonably assume that to the extent we mean anything by
these words, they cause things that* matter* to us and that these
things can be measured. Indeed, “power” is nothing if not the cause of
many things that matter to us without itself being much influenced.
Power, therefore, is the most essential subject of causal analysis.
Power is what dynamical models expose and, indeed, define since
dynamical models necessarily expose causal structure.
Mitigating Power Concentration
How we go about mitigating power concentration depends on what few
things outside of power itself concentrate or dissipate power. These are
likely to be subtle influences, otherwise they would have been exploited
by power to concentrate power. We can be relatively assured that much
power has been invested in discovering these exploits, whether to
self-serve by concentrating power or to dissipate competing power. We
can also be relatively assured that such social engineering has been
based on closed foundation world models. An example of a closed
foundation world model might be just a culture of power seeking embodied
in the transfer of folk knowledge. It may also be a kind of “closed
source” sociology in which a foundation world model is treated as
intellectual property or state secret.
In both cases, the open source Foundation World Model will tend to
mitigate power concentration by its mere existence. For this reason, it
is reasonable to expect powerful interests will be, shall we say,
“interested”.
The inevitable conflicts of interests that arise during the pursuit of
the Foundation World Model can best be addressed by the 3 stages of
competition that expose these conflicts of interest to the light of day
and the most optimal, principled, objective and ruthless model selection
criterion available to us:
The AIC.
Bibliography
World3: Meadows, Donella; Randers, Jorgen; Meadows, Dennis. , A Synopsis: Limits to Growth: The 30-Year Update,
AIC: Solomonoff, R., A Formal Theory of Inductive Inference, 1964
Akaike: Akaike, H, A new look at the statistical model identification, 1974
Found: Sherry Yang, Ofir Nachum, Yilun Du, Jason Wei, Pieter Abbeel, Dale Schuurmans, Foundation Models for Decision Making: Problems, Methods, and Opportunities, 2023
LLMWM: Illya Sutskever, https://youtu.be/NT9sP4mAWEg , 2023
Depend: Dependent and independent variables - Wikipedia
phack: Wasserstein, Ronald L.; Lazar, Nicole A., The ASA Statement on p-Values: Context, Process, and Purpose, 2016
MultiAn: Open Science Collaboration, Estimating the reproducibility of psychological science, 2015
Math: Wigner, E. P., The unreasonable effectiveness of mathematics in the natural sciences, 1960
Godel: Ernest Nagel and James R. Newman , Gödel’s Proof , 1959
HPrize: Marcus Hutter, The Hutter Prize for Lossless Compression of Human Knowledge, 2006
AIXI: Marcus Hutter, An Introduction to Universal Artificial Intelligence, 2024
CPrize: James Bowery, The C-Prize – A prize that solves the artificial intelligence problem, 2005
Resource: Marcus Hutter, Why do you restrict to a single CPU core and exclude GPUs?,
HWLottery: Sara Hooker, The Hardware Lottery, 2020
KC: Illya Sutskever, An Observation on Generalization, 2023
Explain: Phillips, P. Jonathon; Hahn, Carina A.; Fontana, Peter C.; Yates, Amy N.; Greene, Kristen; Broniatowski, David A.; Przybocki, Mark A., Four Principles of Explainable Artificial Intelligence, 2021