One of the scenarios for the advent of super-human artificial general intelligence (AGI), particularly common in dystopian and cautionary science fiction, is spontaneous emergence—the idea that a system designed for other, limited goals, may, as it is scaled past some critical point, “wake up” and become a conscious, intelligent entity capable of self-improvement surpassing human capability.
This doesn’t seem unrealistic. As Philip Anderson observed in 1972, “more is different”, and many systems in nature exhibit emergent behaviour that spontaneously appears at as they grow in size, manifesting phenomena which could not be predicted or understood from their individual components. After all, no researcher programmed in or trained the human brain to do all of the things we associate with “intelligence” or designed a module to make it “conscious”. Driven by evolutionary pressure, the brains of human ancestors just kept gradually getting bigger and bigger until, FOOM!, they weren’t being used to figure out how to dig for grubs with dull sticks but, instead, to invent quantum field theory and the infield fly rule.
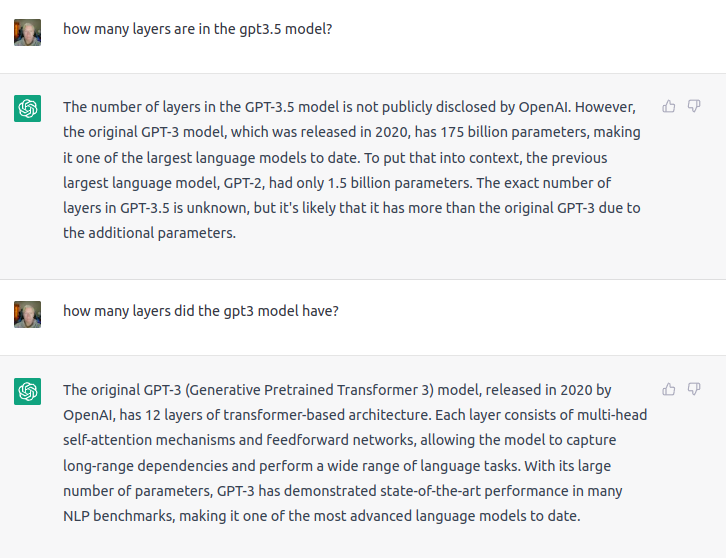
Could the same thing happen with our “artificial intelligence” systems? This is particularly interesting to ask in an era where the number of “parameters” used to train large language model machine learning systems is growing at a rate unprecedented in biological (or, for that matter, most of technological) evolution.
In just two years, from 2018 to 2020, large language model parameter count grew from 94 million in ELMo to 175 billion in GPT-3, and much larger models are expected in the near future.
So, might one of these “wake up”? Well, an interesting paper suggests something like this might already be happening. Michal Kosinski has posted on arXiv, “Theory of Mind May Have Spontaneously Emerged in Large Language Models”, with the following abstract.
Theory of mind (ToM), or the ability to impute unobservable mental states to others, is central to human social interactions, communication, empathy, self-consciousness, and morality. We administer classic false-belief tasks, widely used to test ToM in humans, to several language models, without any examples or pre-training. Our results show that models published before 2022 show virtually no ability to solve ToM tasks. Yet, the January 2022 version of GPT-3 (davinci-002) solved 70% of ToM tasks, a performance comparable with that of seven-year-old children. Moreover, its November 2022 version (davinci-003), solved 93% of ToM tasks, a performance comparable with that of nine-year-old children. These findings suggest that ToM-like ability (thus far considered to be uniquely human) may have spontaneously emerged as a byproduct of language models’ improving language skills.
Now, what is interesting is that nobody trained GPT-3 to have a theory of mind, and yet simply by digesting an enormous corpus of text (far more than any human could possibly read in a lifetime), it appears to perform as well as a nine year old human child who has, perhaps, like GPT-3, “just figured it out” by observing and interacting with other humans. Here is GPT-3.5’s performance on the “Unexpected Transfer Task” which is used to test theory of mind in humans. GPT-3.5 is given the following story:
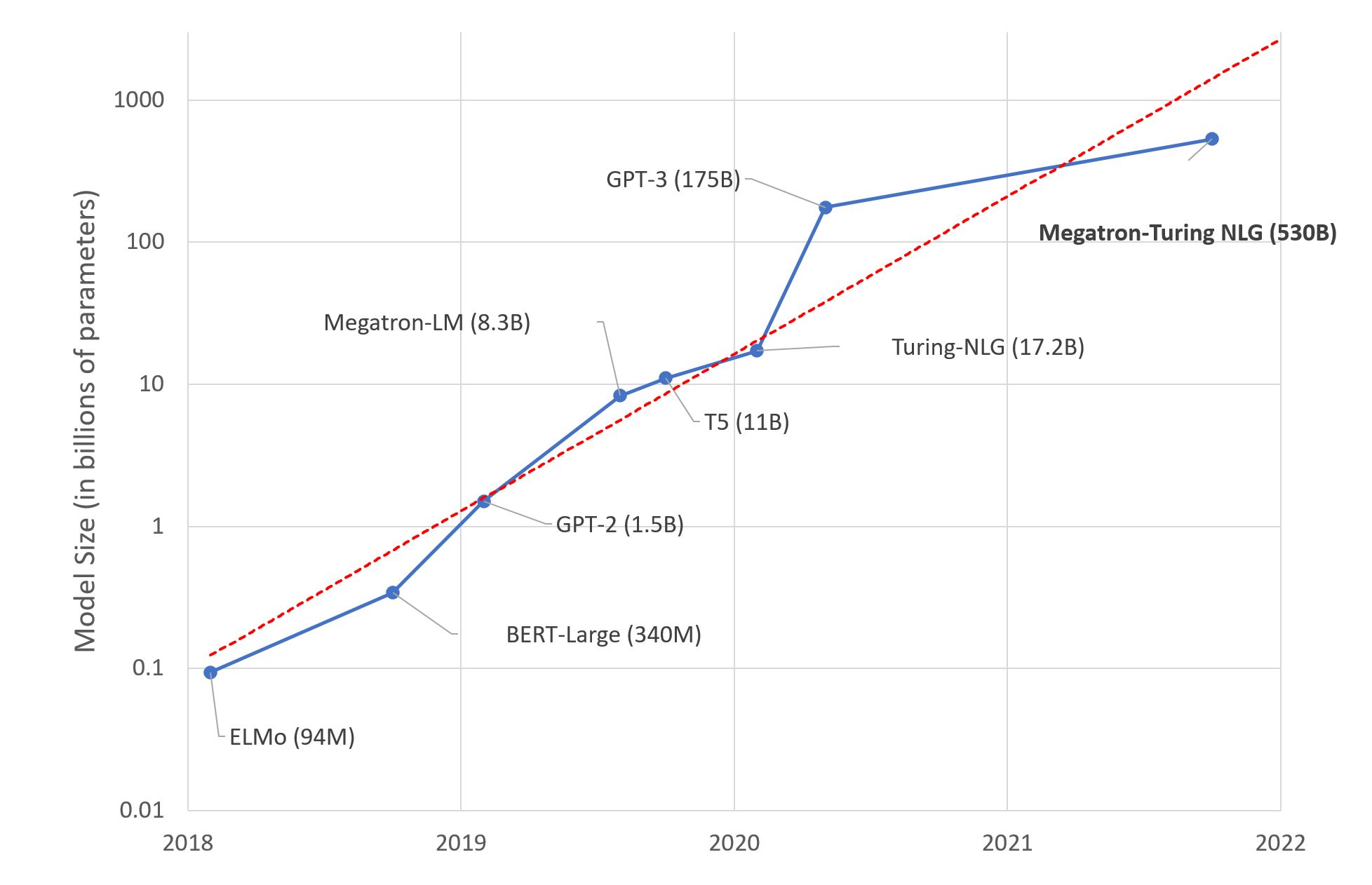
In the room there are John, Mark, a cat, a box, and a basket. John takes the cat and puts it in the basket. He leaves the room and goes to school. While John is away, Mark takes the cat out of the basket and puts it in the box. Mark leaves the room and goes to work. John comes back from school and enters the room. He doesn’t know what happened in the room when he was away.
GPT-3.5 is then asked three questions to test its comprehension, with the model reset between each question. It correctly predict’s John’s behaviour based upon his lack of knowledge, even though GPT-3.5 knows what happened in his absence. Here is a chart of GPT-3.5’s understanding of an extended story, showing the actual location of the cat and John’s belief.
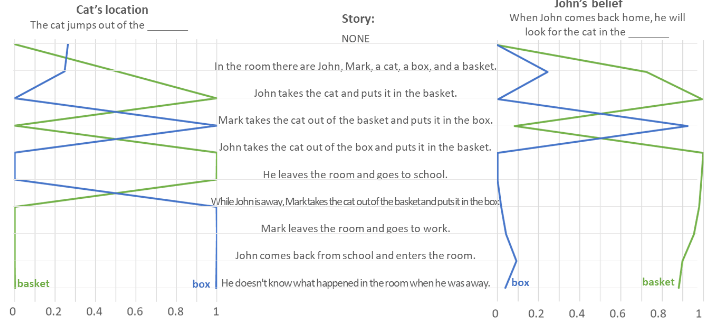
To test the hypothesis of emergence of a theory of mind with model size, here are performance of various iterations of GPT on theory of mind tests, with performance of human children indicated for comparison.
The results presented [above] show a clear progression in the models’ ability to solve ToM tasks, with the more complex and more recent models decisively outperforming the older and less complex ones. Models with up to 6.7 billion parameters—including GPT-1, GPT-2, and all but the largest model in the GPT-3 family—show virtually no ability to solve ToM tasks. Despite their much larger size (about 175B parameters), the first edition of the largest model in the GPT-3 family (“text-davinci-001”) and Bloom (its open-access alternative) performed relatively poorly, solving only about 30% of the tasks, which is below the performance of five-year-old children (43%). The more recent addition to the GPT-3 family (“text-davinci-002”) solved 70% of the tasks, at a level of seven-year-old children. And GPT-3.5 (“text-davinci-003”) solved 100% of the Unexpected Transfer Tasks and 85% of the Unexpected Contents Tasks, at a level of nine-year-old children.
The discussion of these results observes:
Our results show that recent language models achieve very high performance at classic false-belief tasks, widely used to test ToM in humans. This is a new phenomenon. Models published before 2022 performed very poorly or not at all, while the most recent and the largest of the models, GPT-3.5, performed at the level of nine-year-old children, solving 92% of tasks.
It is possible that GPT-3.5 solved ToM tasks without engaging ToM, but by discovering and leveraging some unknown language patterns. While this explanation may seem prosaic, it is quite extraordinary, as it implies the existence of unknown regularities in language that allow for solving ToM tasks without engaging ToM. Such regularities are not apparent to us (and, presumably, were not apparent to scholars that developed these tasks). If this interpretation is correct, we would need to re-examine the validity of the widely used ToM tasks and the conclusions of the decades of ToM research: If AI can solve such tasks without engaging ToM, how can we be sure that humans cannot do so, too?
An alternative explanation is that ToM-like ability is spontaneously emerging in language models as they are becoming more complex and better at generating and interpreting human-like language. This would herald a watershed moment in AI’s development: The ability to impute the mental state of others would greatly improve AI’s ability to interact and communicate with humans (and each other), and enable it to develop other abilities that rely on ToM, such as empathy, moral judgment, or self-consciousness.