It’s 1997 only instead of the Netscape interface to the World Wide Web, it’s the large language model front end to an explosion of power-hungry matrix multipliers “in the cloud”.
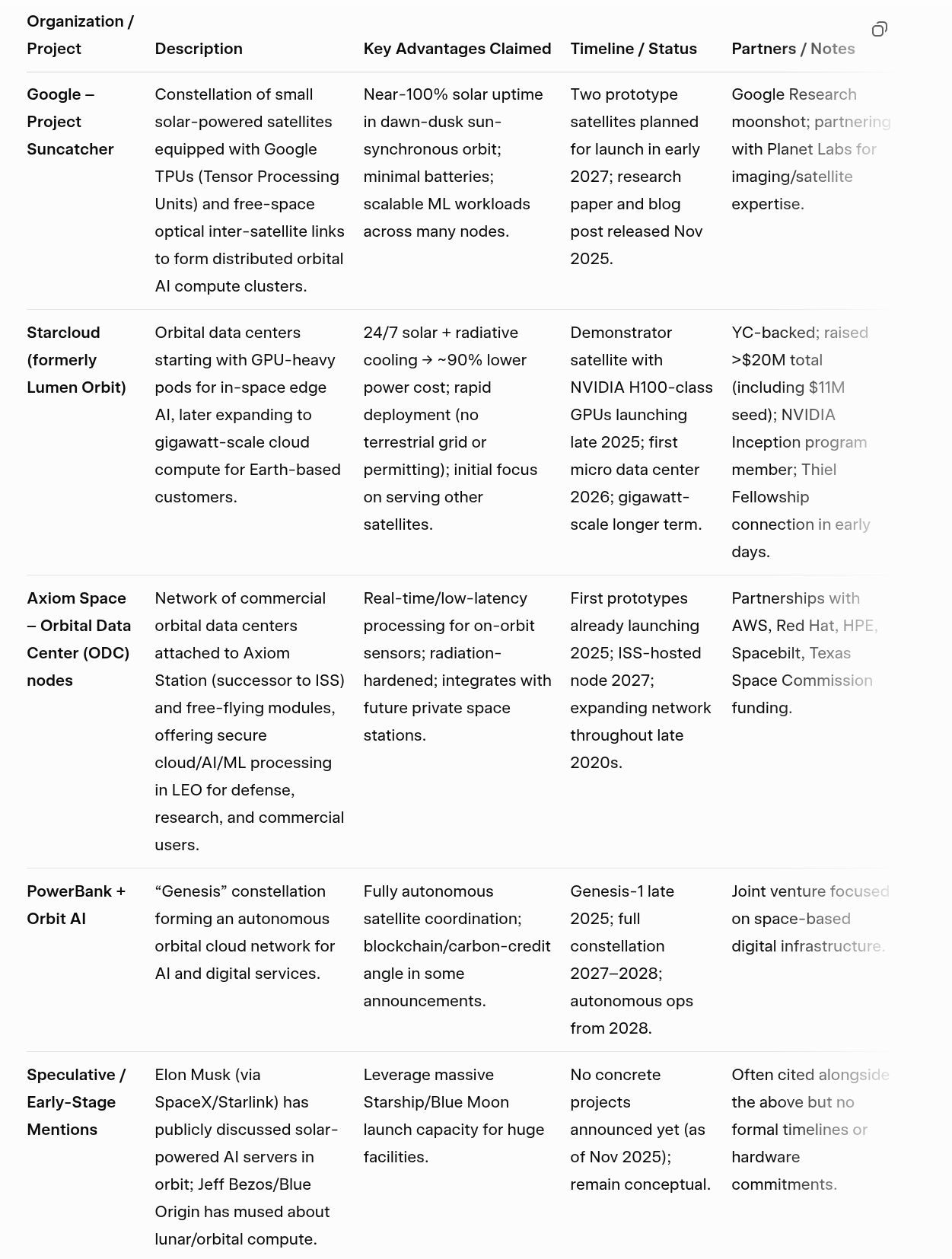
Generative AI demand growth beyond world name plate capacity for electrical generation is likely to out pace that indicated by the following thematic map:

Yes, the hysteria that hit in 1997 was largely fluff. So is the current large language model hysteria. Even so, there will, at the very least, be a temporary peak-load electric power price rise in the next few years. It may even be a price shock. Moreover, there is good reason to believe that even if there are great advances in the efficiency of AI systems, the tax structure favoring rentiers over labor will result in a voracious AI appetite for energy. Rentiers will be literally throwing money at anyone who can, in turn, throw money at increasing AI capacity.
What people are missing here is that, just as the cost of improving scientific models goes vertical (asymptotic), so, too, does the cost of improving any model of the world, including generative AI models. The reason for this is that generative AI models, in the final analysis, rely on scientific models of the world (world models) in the general sense of the natural sciences. Moreover, just as squeezing that last bit of accuracy out of a scientific model pays huge dividends, so, too, will squeezing that last bit of accuracy out of generative AI models pay huge dividends. “An ounce of prevention…” is a gross understatement when it comes to quality in making intelligent decisions. This will sustain the explosion in demand for electricity beyond the present terminal hysteria.
So Keith Lofstrom’s approach in Server Sky starts to look like it may be inevitable and a lot sooner than 2030, which is when it might otherwise seem reasonable to expect it to be deployed at scale. The basic idea is to mass produce, and deploy in high orbit, constellations of “thinsats”:
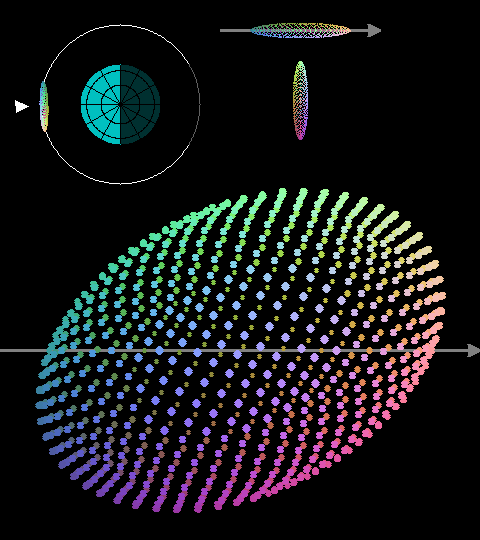
Each thinsat weighs about 5 grams. It incorporates solar cells, computation, telecommunications, heat-sink radiator and, interestingly, quasi-reactionless elecrochromic thrusters for station keeping. Here is a diagram of thinsat version 6:
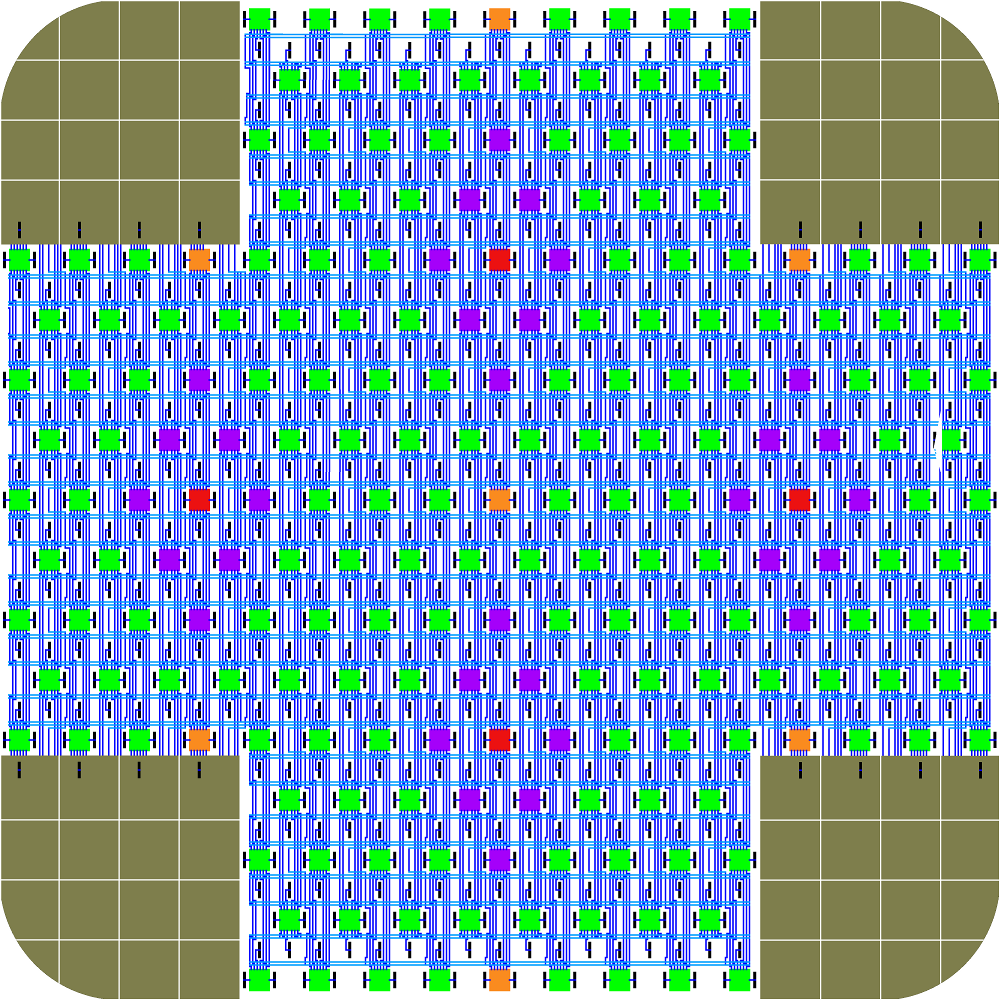
By “elecrochromic” Lofstrom means a solid state device that varies between reflective and dark/opaque, to work like an integrated set of solar sails at a very small scale. Light pressure only. No fuel needed.
Quoting Lofstrom:
Server Sky is speculative. The most likely technical showstopper is radiation damage. The most likely practical showstopper is misunderstanding. Working together, we can fix the latter.
Radiation damage risk brings to mind Gallium Arsenide’s:
- Relative radiation resistance
- Utility in solar cells
- Utility in telecommunications (ie: with Earth and other thinsats)
- High electron mobility for computation
- Dielectric advantages for smaller integrated circuits (which is a big reason Seymour Cray favored GaAs)
Of course, GaAs fabs have a lot of catching up to do if they are going to compete with whatever radiation shielding might be available to silicon thinsats, but if the GaAs fab guy I talked to at the demise of Cray Computer Corp. is to be believed, the potential is there for a revolution in electronics, given enough hysterical investment capital to overcome The Hardware Lottery.

 Movie CLIP (1997) HD")