In a paper published on ArXiV on 2021-10-30, “Trojan Source: Invisible Vulnerabilities”, University of Cambridge researchers Nicholas Boucher and Ross Anderson report a new attack vector which affects essentially any programming language which accepts Unicode characters in its source code, including the UTF-8 encoding which is becoming ubiquitous.
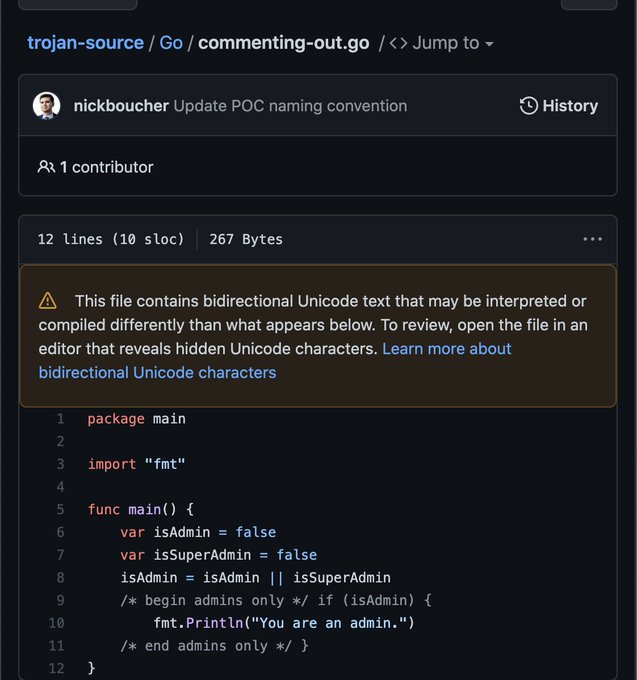
The trick is simple: use Unicode bidirectional text formatting control codes to write text which the compiler interprets in a way which differs from how it appears to a human reading the code. The abstract describes the method as follows.
We present a new type of attack in which source code is maliciously encoded so that it appears different to a compiler and to the human eye. This attack exploits subtleties in text-encoding standards such as Unicode to produce source code whose tokens are logically encoded in a different order from the one in which they are displayed, leading to vulnerabilities that cannot be perceived directly by human code reviewers. ‘Trojan Source’ attacks, as we call them, pose an immediate threat both to first-party software and of supply-chain compromise across the industry. We present working examples of Trojan-Source attacks in C, C++, C#, JavaScript, Java, Rust, Go, and Python. We propose definitive compiler-level defenses, and describe other mitigating controls that can be deployed in editors, repositories, and build pipelines while compilers are upgraded to block this attack.
Other forms of deceptive code attacks are also discussed, including invisible characters and homoglyph attacks (replacing a character with another which is visually similar, for example the Latin alphabet “H” and the Cyrillic “Н”).
It will be essential that compilers and code auditing tools check for the presence of these Unicode tricks in source code and flag them for programmers and software testers. It will probably not be long before public code repositories such as GitHub start screening code for deceptive Unicode constructions.