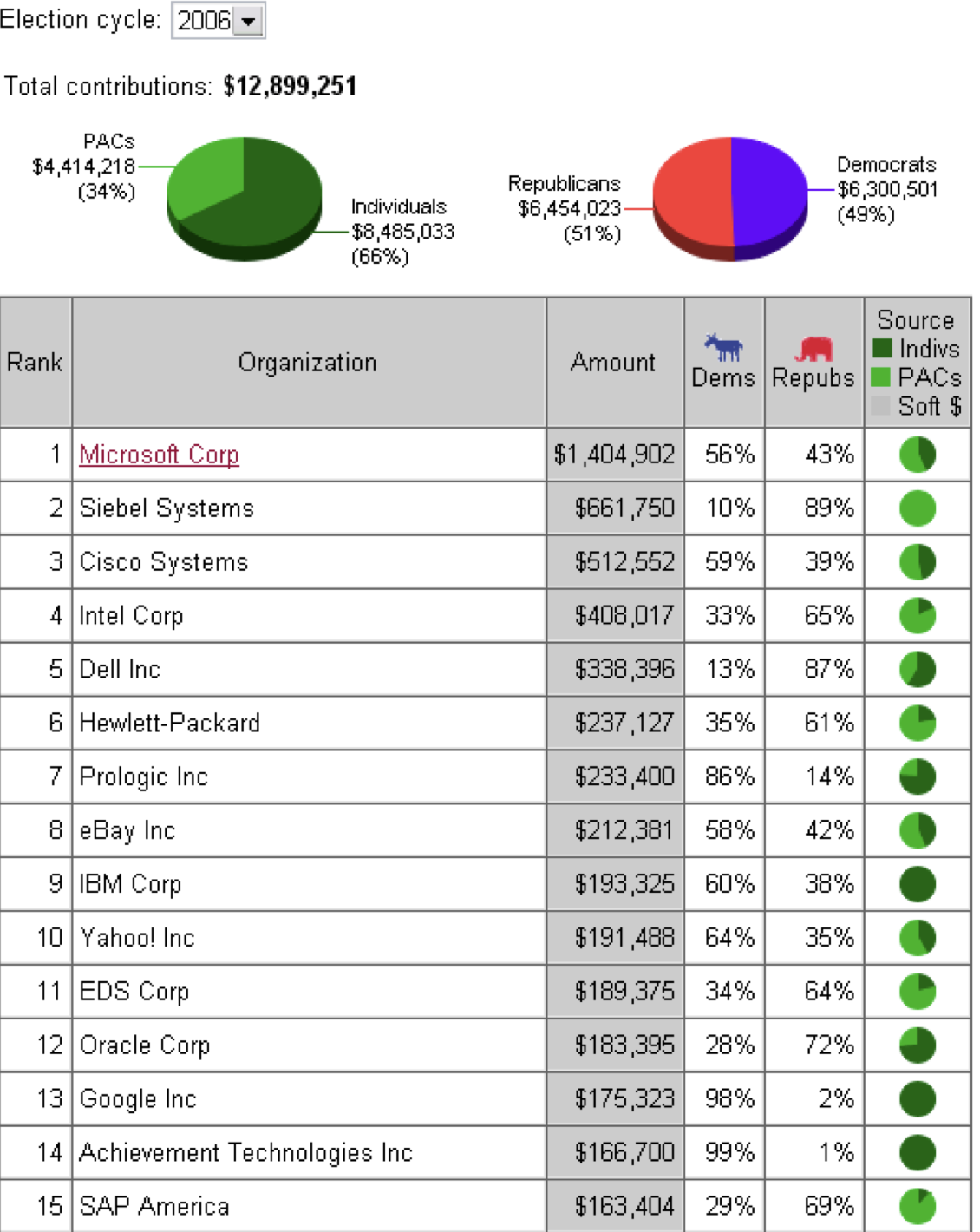
When I wrote “The Digital Imprimatur” almost twenty years ago (published on 2003-09-13), I was motivated by the push for mandated digital rights management with hardware enforcement, attacks on anonymity on the Internet, the ability to track individuals’ use of the Internet, and mandated back-doors that defeated encryption and other means of preserving privacy against government and corporate surveillance. This was informed by the “crypto wars” of the 1990s and, in particular, the attempt by the Clinton regime in the U.S. to mandate the “Clipper chip” with “key escrow” and a built-in backdoor which would allow “law enforcement” to intercept all private communications foolish enough to use it. In 2003, with terrorism hysteria in full force and the so-called PATRIOT Act being seen as just the first act in an epochal power grab by coercive government of the rights to privacy of their once-citizens, now subjects and consumers, I warned of an emerging alliance between Big Brother and Big Media (the term “Big Tech” not having then emerged) to “put the Internet genie back in the bottle”. This was exemplified by a project underway at Microsoft, code named “Palladium” and later officially dubbed the “Next-Generation Secure Computing Base for Windows”, which envisioned forcing personal computer manufacturers, in order to be able to run Microsoft Windows, to incorporate hardware-level protection to block access by the nominal owner of the computer to “sealed storage” containing proprietary programs and data. This would not only enforce digital rights management, prevent software piracy, but allow Microsoft to block the use of non-Microsoft operating systems which did not bear the Microsoft signature at boot time. Such systems could contain back-doors to eavesdrop on users’ private information and communications, with the user unable to detect their presence or circumvent their operation.
In “The Digital Imprimatur”, I predicted “the overwhelming majority of new computer systems sold in the year 2010 to include Trusted Computing functionality”. Well, in this case even I underestimated the ham-fisted blundering ignorance of Microsoft designers, the utter incompetence of their software implementation, and the zombie-shuffling pace of government action in the United States, so by a combination of all of these, in the 2000s we managed to dodge this bullet. But while my forecasts are often (way) too early, they have a way of eventually coming to pass.
That was then. This is now. Slavers are stupid, but very persistent. “Look out, here it comes again!
This time it’s called “Web Environment Integrity” (WEI), and it comes, not from Microsoft but from the company that traded in their original slogan of “Don’t be evil” for “What the Hell, evil pays a lot better!”—Google.
So, what is WEI? Let’s start with a popular overview from Ars Technica.
Google’s newest proposed web standard is… DRM? Over the weekend the Internet got wind of this proposal for a "Web Environment Integrity API. " The explainer is authored by four Googlers, including at least one person on Chrome’s “Privacy Sandbox” team, which is responding to the death of tracking cookies by building a user-tracking ad platform right into the browser.
The intro to the Web Integrity API starts out: “Users often depend on websites trusting the client environment they run in. This trust may assume that the client environment is honest about certain aspects of itself, keeps user data and intellectual property secure, and is transparent about whether or not a human is using it.”
The goal of the project is to learn more about the person on the other side of the web browser, ensuring they aren’t a robot and that the browser hasn’t been modified or tampered with in any unapproved ways. The intro says this data would be useful to advertisers to better count ad impressions, stop social network bots, enforce intellectual property rights, stop cheating in web games, and help financial transactions be more secure.
⋮
Google’s plan is that, during a webpage transaction, the web server could require you to pass an “environment attestation” test before you get any data. At this point your browser would contact a “third-party” attestation server, and you would need to pass some kind of test. If you passed, you would get a signed “IntegrityToken” that verifies your environment is unmodified and points to the content you wanted unlocked. You bring this back to the web server, and if the server trusts the attestation company, you get the content unlocked and finally get a response with the data you wanted.
Now let’s take a peek at the cited “Web Environment Integrity Explainer” posted on GitHub.
Users often depend on websites trusting the client environment they run in. This trust may assume that the client environment is honest about certain aspects of itself, keeps user data and intellectual property secure, and is transparent about whether or not a human is using it. This trust is the backbone of the open internet, critical for the safety of user data and for the sustainability of the website’s business.
Mother of babbling God—this is the first paragraph of the document. The fundamental principle of designing any network application, known, applied, and inevitably exploited when forgotten for at least half a century now is “Don’t trust the client.”. A server communicating over a network to a client not under its control must always assume the client is malicious, verify everything independently, guard against “man in the middle” attacks, and defend itself from denial of service attacks. To “assume that the client environment is honest” might be called the Original Sin of network application security, and yet here, in a paper authored by four Google employees, in the very first paragraph, they assert “This trust is the backbone of the open internet, critical for the safety of user data and for the sustainability of the website’s business.”
Now let’s look at:
Some examples of scenarios where users depend on client trust include:
- Users like visiting websites that are expensive to create and maintain, but they often want or need to do it without paying directly. These websites fund themselves with ads, but the advertisers can only afford to pay for humans to see the ads, rather than robots. This creates a need for human users to prove to websites that they’re human, sometimes through tasks like challenges or logins.
- Users want to know they are interacting with real people on social websites but bad actors often want to promote posts with fake engagement (for example, to promote products, or make a news story seem more important). Websites can only show users what content is popular with real people if websites are able to know the difference between a trusted and untrusted environment.
- Users playing a game on a website want to know whether other players are using software that enforces the game’s rules.
- Users sometimes get tricked into installing malicious software that imitates software like their banking apps, to steal from those users. The bank’s internet interface could protect those users if it could establish that the requests it’s getting actually come from the bank’s or other trustworthy software.
The means to implement this “trust” mean the end of privacy, tattooing an “Internet licence plate” on the user identifying everything they do (and denying them access should they offend the powers that be), locking out users’ ability to customise software running on computers that are their own property, and to filter the content presented to them, becoming passive consumers of what their corporate and government masters permit them to see.
Congratulations, Google, you’ve just invented U.S. television in the age of the three networks and before the VCR. I wonder if this time they’ll even allow you to turn down the volume when a commercial is playing.
Among the Goals of the explainer we find:
Allow web servers to evaluate the authenticity of the device and honest representation of the software stack and the traffic from the device.
This is the “computer certificate” I discussed in “The Digital Imprimatur”. It verifies that the user is running a top-to-bottom “software stack” in which all components are signed by their vendors and have not been modified in any way, and are running on hardware that refuses to run non-certified software. What does this mean if you’re a monopolist such as, say, Google, who wishes to remain one until the stars burn out?
Look back at the first bullet point of “examples of scenarios” above. There goes your ad blocker, serf. No more web crawlers by Google competitors, as they’re not certified as human. Then, perhaps, the browser (certified unmodified) won’t let you scroll past the auto-play ad without spending a specified time with it on screen. Use another browser? Forget it—Google won’t grant it a certificate that allows it to access sites using Web Integrity unless it also reduces its users to passive consumers. What about renegade Web sites that do not require WEI certification for access? Why, Google will simply designate them “insecure” and decline to index them, rendering them effectively invisible on the Internet.
Once every user has been forced to use WEI-compliant hardware and software, the screw can be turned tighter still. Google’s browser and others they certify can refuse to display content from sites which do not enforce WEI attestation for access, and cloud service providers, content distribution networks, and security front-ends such as Cloudflare can refuse to transmit content from sites which decline to require WEI.
From there, it’s a baby step for WEI-certified browsers to refuse to display content which does not bear a document certificate signed by an authorised “trust provider”. The Digital Imprimatur will now be fully implemented and “all that we have known and cared for, will sink into the abyss of a new Dark Age made more sinister, and perhaps more protracted, by the lights of perverted science.”
References:
- “The Digital Imprimatur”
- “Web Environment Integrity Explainer” at GitHub
- Web Environment Integrity API at GitHub
- “Web Environment Integrity API Draft” at GitHub
- Google Chrome “Intent to Prototype: Web environment integrity API”