The HumesGuillotine README – which I’ve re-oriented (from the more narrowly focused & now-defunct OckhamsGuillotine) to the post-ChatGPT hysterics about AGI “ethics”:
This repository is a series of competitions toward rigorous ethics in AGI founded on Hume’s Guillotine: Separating the question of what IS from what OUGHT to be the case.
Artificial General Intelligence unifies IS with OUGHT. In Marcus Hutter’s rigorous top down AGI theory, AIXI, Algorithmic Information Theory provides the IS and Sequential Decision Theory provides the OUGHT. Another way of stating that is Algorithmic Information Theory provides what IS the case in the form of scientific knowledge. Sequential Decision Theory provides what OUGHT to be the case in the form of engineering: Scientific knowledge applied by decision-makers.
Out of all so-called “Information Criteria” for model selection, the Algorithmic Information Criterion is the best we can do in scientific discovery relative to a given set of observations. This has been known since the 1960s. How it works is the essence of simplicity known as Ockham’s Razor: Pick your data however you like, and find the smallest algorithm that generates all of that data – leaving nothing out: Not even what you consider “noise” or “errors in measurement”. This is lossless compression of your data. The reason you keep all “errors in measurement” – the reason you avoid lossy compression – is to avoid what is known as “confirmation bias” or, what might be called “Ockham’s Chainsaw Massacre”. Almost all criticisms of Ockham’s Razor boil down to mischaracterizing it as Ockham’s Chainsaw Massacre. The remaining criticisms of Ockham’s Razor boil down to the claim that those selecting the data never include data that doesn’t fit their preconceptions. That critique may be reasonable but it is not an argument against the Algorithmic Information Criterion, which only applies to a given dataset. Models and data are different. Therefore model selection criteria are qualitatively different from data selection criteria.
Yes, people can and will argue over what data to include or exclude – but the Algorithmic Information Criterion traps the intellectually dishonest by making their job much harder since they must include exponentially much more data that is biased towards their particular agenda in order to wash out data coherence (and interdisciplinary consilience) in the rest of the dataset. The ever-increasing diversity of data sources identifies the sources of bias – and then starts predicting the behavior of data sources in terms of their bias, as bias. Trap sprung! This is much the same argument as that leveled against conspiracy theories: At some point it becomes simply impractical hide a lie against the increasing diversity of observations and perspectives.
Hume’s Guillotine is concerned only with discovering what IS the case via the Algorithmic Information Criterion for causal model selection. Objective scoring of a scientific model by the Algorithmic Information Criterion is utterly independent of how the model was created. In this respect, Hume’s Guillotine doesn’t even care whether computers were used to create the model, let alone which machine learning algorithms might be used.
This repository contains a series of datasets (the first of which is at LaboratoryOfTheCounties) to create the best unified model of social causation.
See the Nature video “Remodelling machine learning: An AI that thinks like a scientist” and its cited Nature journal article “Causal deconvolution by algorithmic generative models”.
Background
There are a number of statistical model selection criteria that attempt to walk the tightrope between “overfitting” and “confirmation bias”. Overfitting loses predictive power by simply memorizing the data without generalizing. Confirmation bias loses predictive power by throwing out data that doesn’t fit the model – data that may point to a more predictive model. Model selection criteria are generally called “information criteria”, e.g. BIC is “Bayesan Information Criterion”, AIC is “Akaike Information Criterion”, etc. What they all have in common, is the statistical nature of their information. That is to say, they are all based, directly or indirectly, on Shannon Information Theory.
Here’s the critical difference in a nutshell:
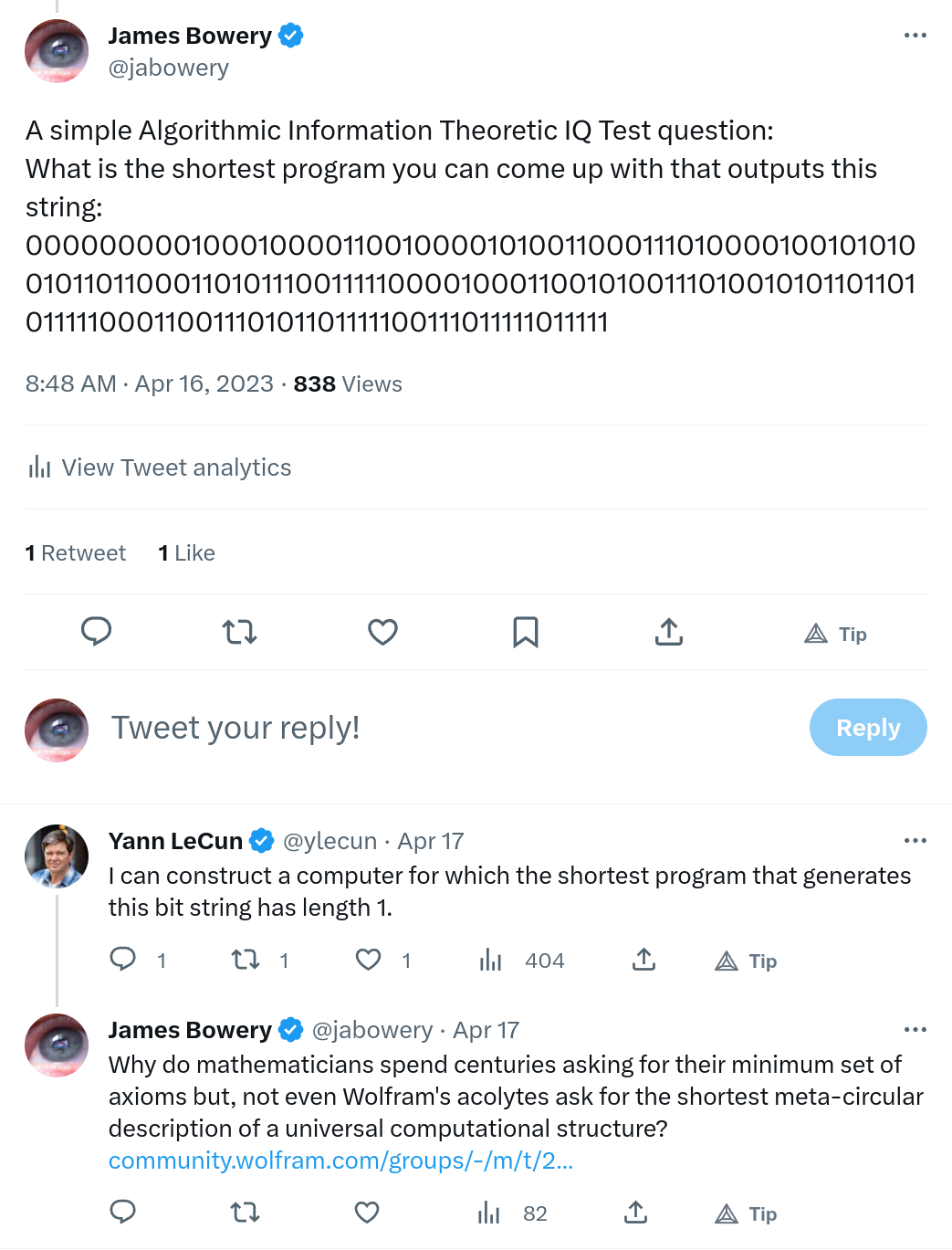
Shannon Information regards the first billion bits of the number Pi to be random. That is to say, there is no description of those bits in terms of Shannon Information that is shorter than a billion bits.
Algorithmic Information regards the first billion bits of the number Pi to be the shortest algorithm that outputs that precise sequence of bits.
Now, which of these two theories of “information” would you trust to predict the next bit of Pi?
Data-driven science frequently starts with statistical notions of information but in order to make predictions about the real world, they eventually take the form of algorithms that simulate the causal structures of the world being modeled. It is at this transition from Shannon Information to Algorithmic Information that causation necessarily enters the model and does so based on the assumption of any natural science: That reality is structured in such a way that we can use arithmetic to predict future observations based on past observations.
 Could Be Key--Yikes!")
")
")