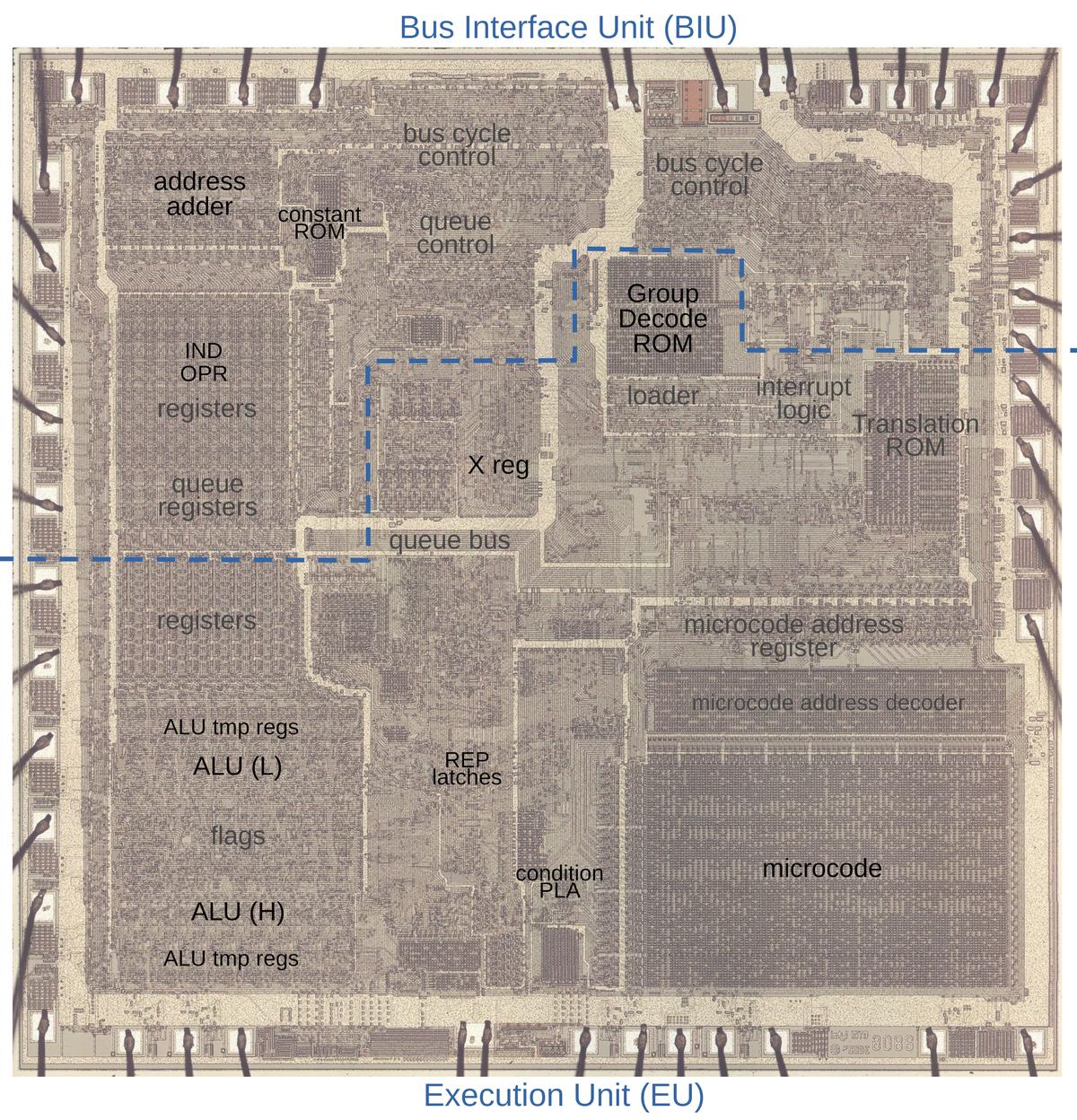
The Intel 8086 microprocessor, introduced in 1978, was Intel’s first 16-bit microprocessor. It extended the architecture of the 8-bit 8080 to allow addressing up to one megabyte of memory with a segmented address scheme, full 16 bit arithmetic, multiply and divide instructions, and support for coprocessors such as the 8087, which supported hardware floating point arithmetic. Another innovation of the 8086 was what were called “string instructions”, in which blocks of memory as large as 64 kilobytes can be moved, cleared, and compared with a single instruction that runs as fast as the memory can cycle, many times faster than a written-out loop in machine language. A six-instruction memory byte move loop:
loop mov al,[si] ; Load AL from [src]
mov [di],al ; Store AL to [dst]
inc si ; Increment src
inc di ; Increment dst
dec cx ; Decrement len
jnz loop ; Repeat the loop
can be replaced with:
cld ; Clear the Goddam decrement bit
rep ; Repeat until CX = 0
movsb ; Move the data block
where the “rep” instruction modifies the subsequent “movsb” instruction (move bytes) to repeat, counting down the CX register for each byte until it is zero. The written-out loop does 11 memory accesses for each byte it moves, nine to fetch the instructions and two to actually load and store the byte, while the “rep movsb” does only the load and store for each byte.
This is a dramatic improvement in efficiency, but poses a problem. Since a repeated instruction can perform up to up to 65535 operations, given the speed of memory at the time, a string instruction could take a substantial part of a second to execute, longer if the memory was slow and imposed wait states on the processor. If the CPU locked up until the repeat instruction was done, it could not process interrupts from I/O devices, leading to lost data from, for example, user keystrokes or characters arriving from serial ports. So, a repeated instruction must be able to be interrupted, then resumed when interrupt processing is complete. But recall that, for example, a move instruction can operate on either 16 bit words or individual 8 bit bytes, can run with addresses either ascending or descending (the dreaded and detested “direction flag”), and 16 bit words may be misaligned with respect to physical memory, which forces two separate byte accesses for each word (programmers try to avoid this because of the performance hit, but if you do it, it still has to work). This makes the process of adjusting everything when the instruction is interrupted exquisitely complicated, with the counter and pointer registers needing to be adjusted by anywhere from −3 to +2 at each interrupt, which is done by the following piece of silicon magic.

All of this and more is explained in Ken Shirriff’s latest installment of his magnificent series reverse-engineering the 8086 at the transistor level, “The microcode and hardware in the 8086 processor that perform string operations”. The explanation of the clever way this is implemented in the processor’s microcode is particularly enlightening.
All x86 architecture processors, 45 years later, support these instructions and must cope with the complexity they create (compounded by extensions to allow moving data 32- and 64-bits at once).
See also the 2022-11-29 post “Fixing a Bug in the Intel 8086 Processor Silicon”.
