Answer from http://grok.com:
Combining these elements—(1) the Hutter Prize’s focus on limited but general-purpose computation for language model learning, (2) Sara Hooker’s “Hardware Lottery” thesis, (3) the empirical nature of ML scaling laws, and (4) the significant disparity in capital between the Hutter Prize and initiatives like xAI’s Memphis ML center—offers an insightful perspective on the landscape of AI research and development:
Analysis:
- Hutter Prize’s Approach:
The Hutter Prize emphasizes efficiency and ingenuity within constrained computational environments, specifically for text compression. This approach aligns with solving complex problems with minimal resources, highlighting the value of algorithm optimization over sheer computational power.
2. Sara Hooker’s “Hardware Lottery”:
Hooker’s thesis suggests that much of the success in AI research might be due to serendipitous alignment with available hardware rather than the inherent superiority of the algorithms themselves. This implies that the Hutter Prize’s focus could be seen as a counter-narrative or a challenge to the hardware lottery, promoting research where hardware constraints lead to more universal, hardware-agnostic solutions.
3. Empirical Nature of ML Scaling Laws:
The scalability of machine learning models often follows empirical laws, where performance improvements are observed with increased scale (more data, larger models, more compute). However, these laws are not theoretically guaranteed, and there’s a risk of diminishing returns or unexpected plateaus. The Hutter Prize, by contrast, operates under the premise that significant advancements can be made without scaling up computational resources, potentially offering insights into where these scaling laws might not hold or where efficiency can trump scale.
4. Capital Disparity:
The Hutter Prize operates with an endowment far less than what is allocated to a single AI research center like Memphis ML. This stark contrast in funding underscores different philosophies in AI research:
Small, Focused Funding: The Hutter Prize demonstrates that impactful research can come from very constrained resources, potentially leading to innovations in algorithmic efficiency.
Large Scale Investment: Conversely, centers like Memphis ML center invest in the belief that scaling is key to breakthroughs, supported by empirical scaling laws, but this comes with risks as outlined by Hooker’s thesis.
Implications for Capital Allocation and Research Direction:
Risk Mitigation through Diversification: xAI and similar organizations might benefit from not only investing in large-scale, high-resource projects but also in smaller, more constrained research akin to the Hutter Prize’s ethos. This could hedge against the risks of the hardware lottery and the empirical unpredictability of scaling laws.
Innovation in Efficiency: The Hutter Prize could inspire research into more efficient algorithms that perform well under hardware constraints, potentially leading to breakthroughs that are more universally applicable across different hardware environments. This could be particularly valuable if scaling laws begin to show diminishing returns or if there’s a shift towards more resource-efficient AI due to environmental or economic pressures.
Reevaluation of Success Metrics: There’s a need to look beyond performance scales based purely on computational power. Success might also be measured by how well a model performs relative to the resources it consumes, a metric that the Hutter Prize implicitly endorses.
Potential for New Research Paradigms: The combination of these factors might push towards new paradigms where the focus isn’t only on scaling but on smart scaling, where efficiency, generality, and adaptability are equally prized, potentially leading to more sustainable and widely applicable AI technologies.
In summary, while the Memphis ML center represents one end of the spectrum with its focus on scaling and empirical laws, the Hutter Prize represents another, emphasizing efficiency and generalization within constraints. The interplay between these approaches could lead to a richer, more nuanced landscape for AI research, where capital is allocated not just based on current trends but also on potential future shifts in technology and methodology.


 ORIGINAL TRAILER [HD 1080p]")



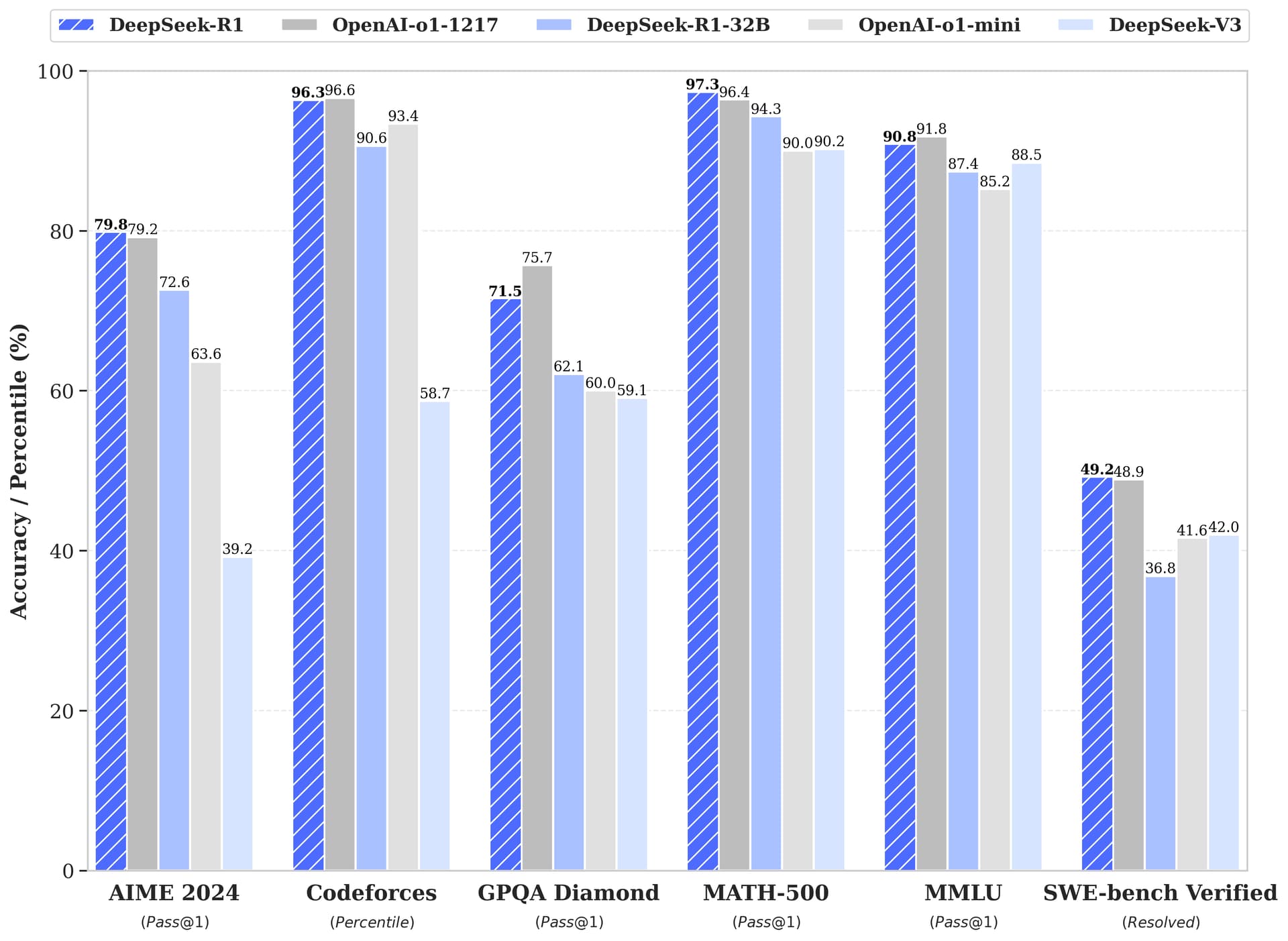


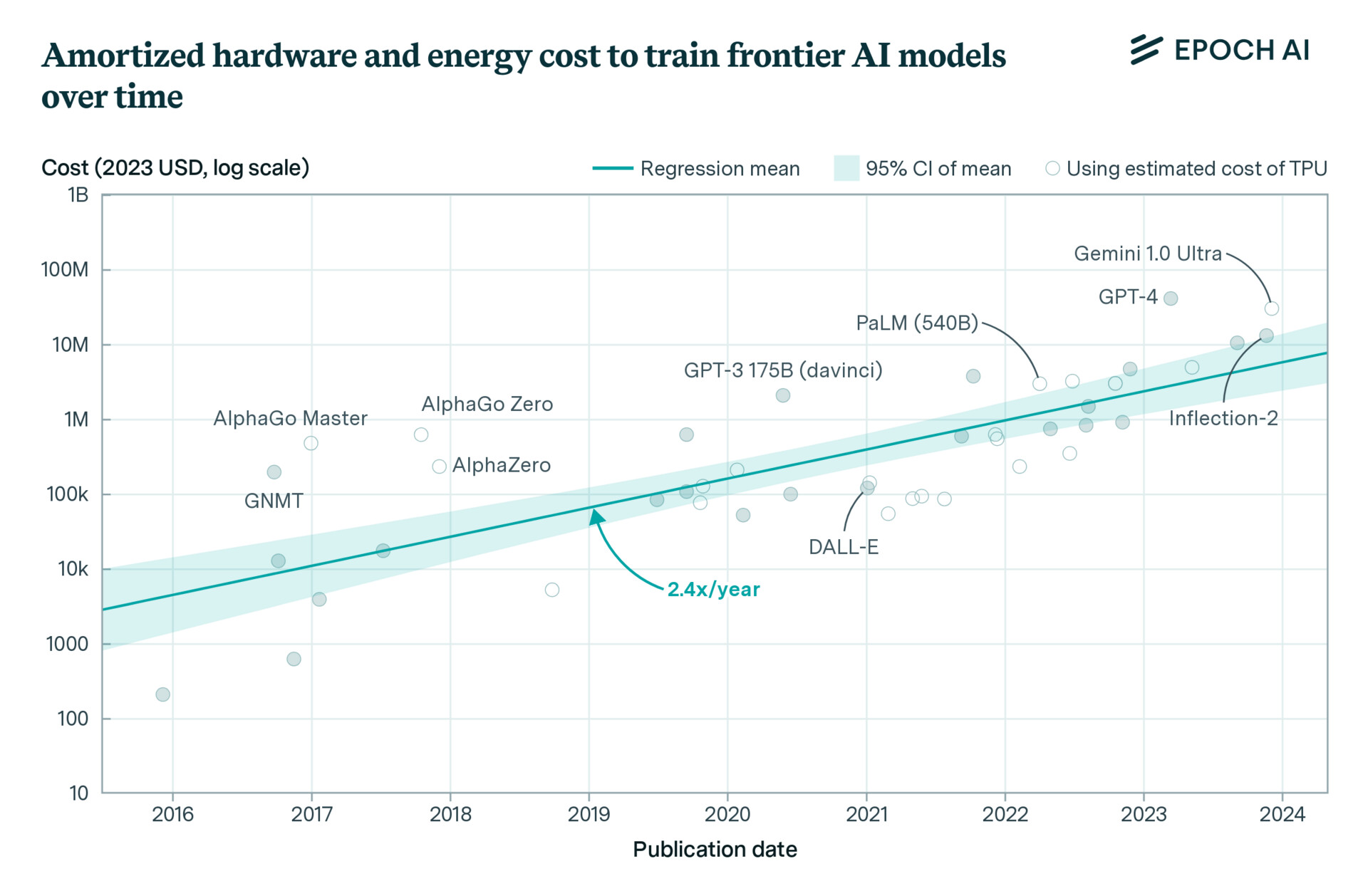
")