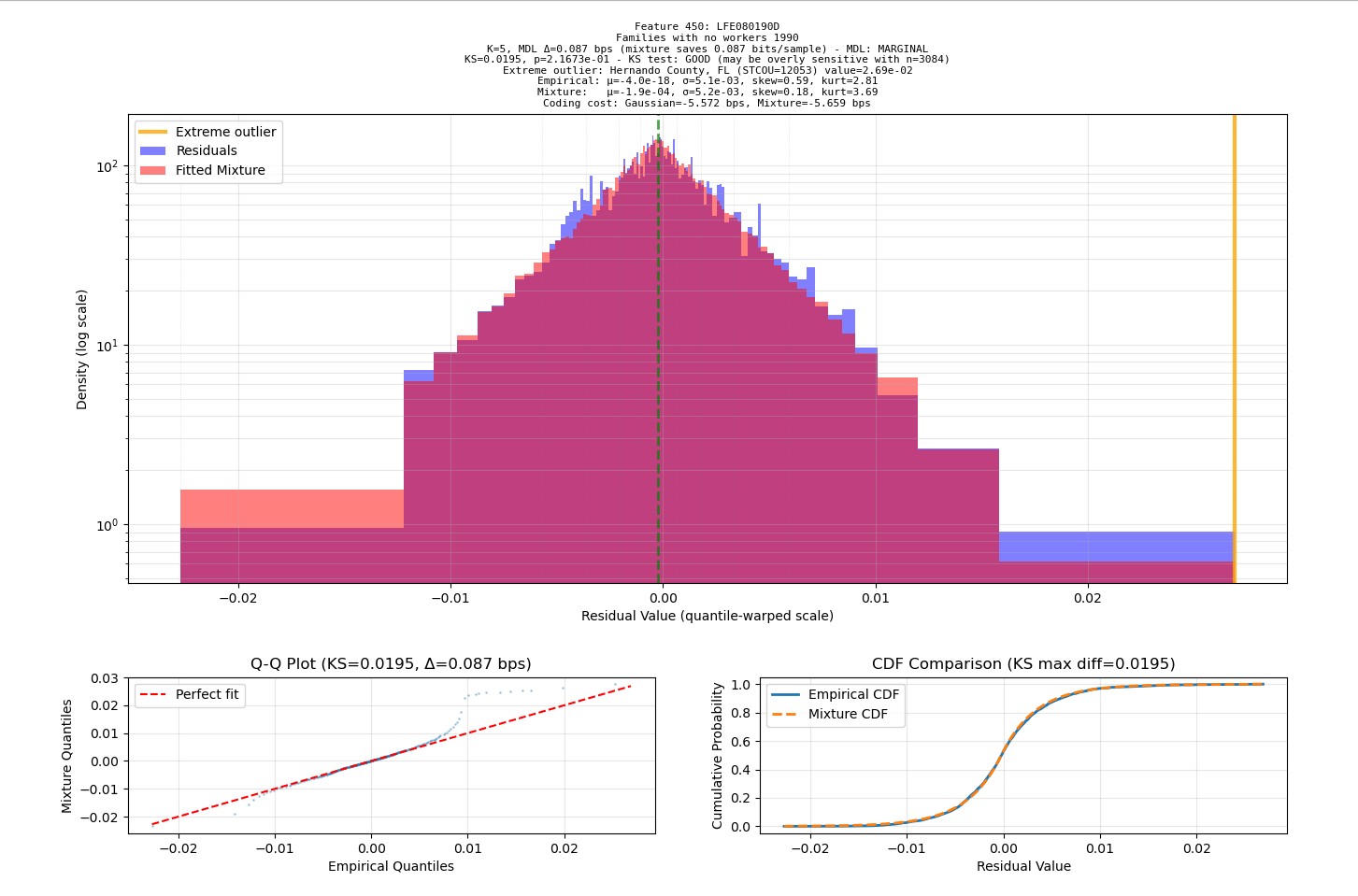
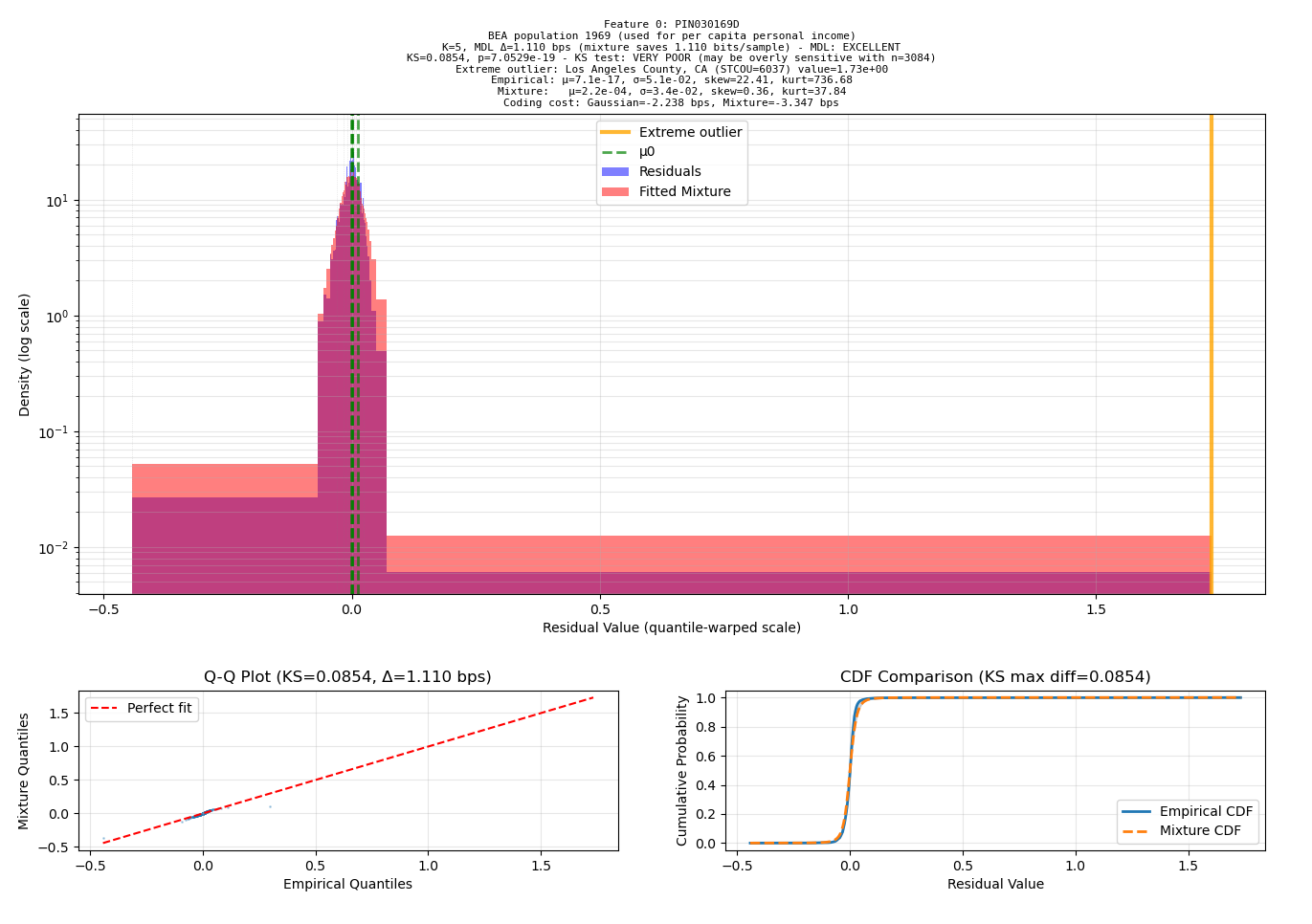
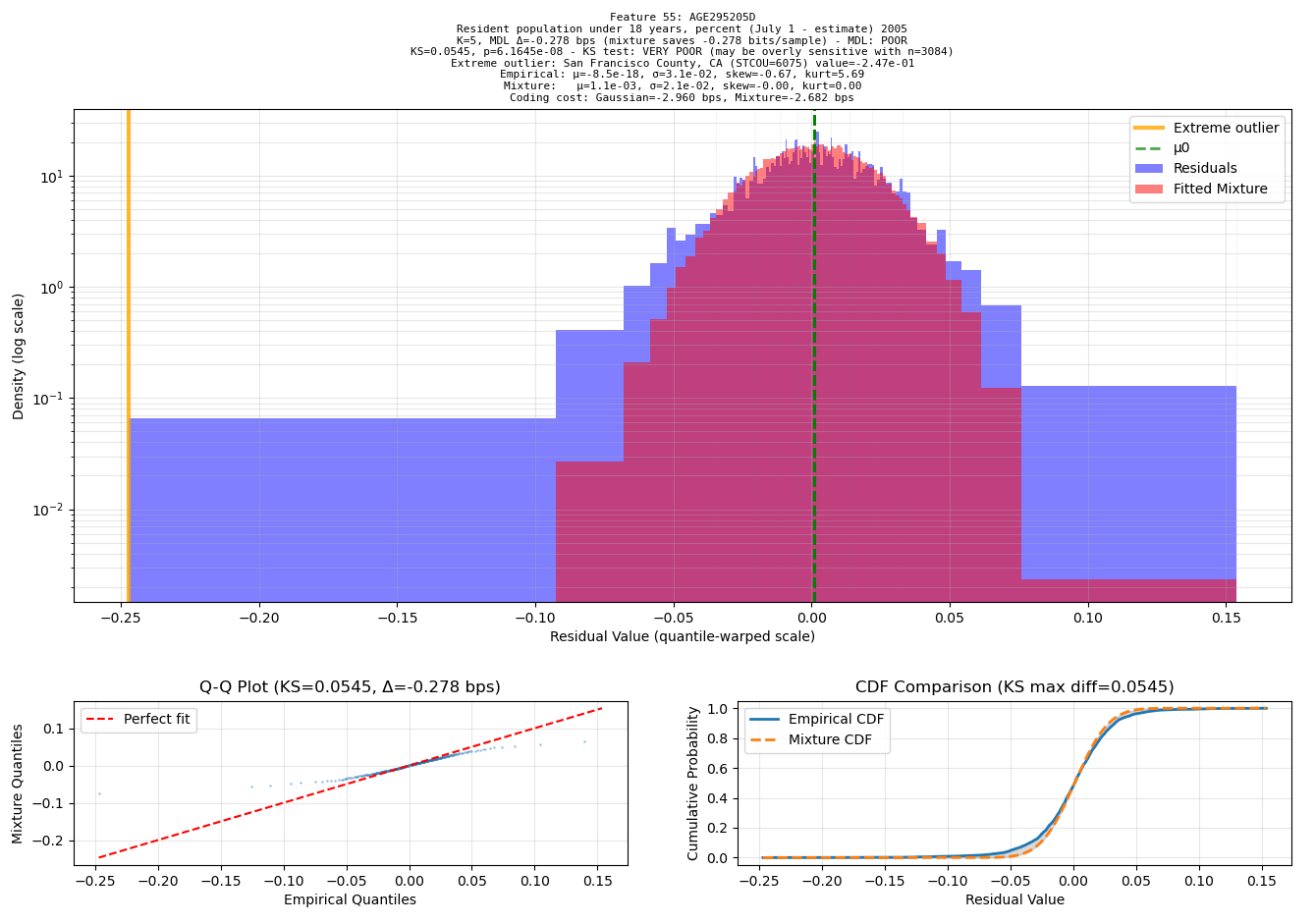
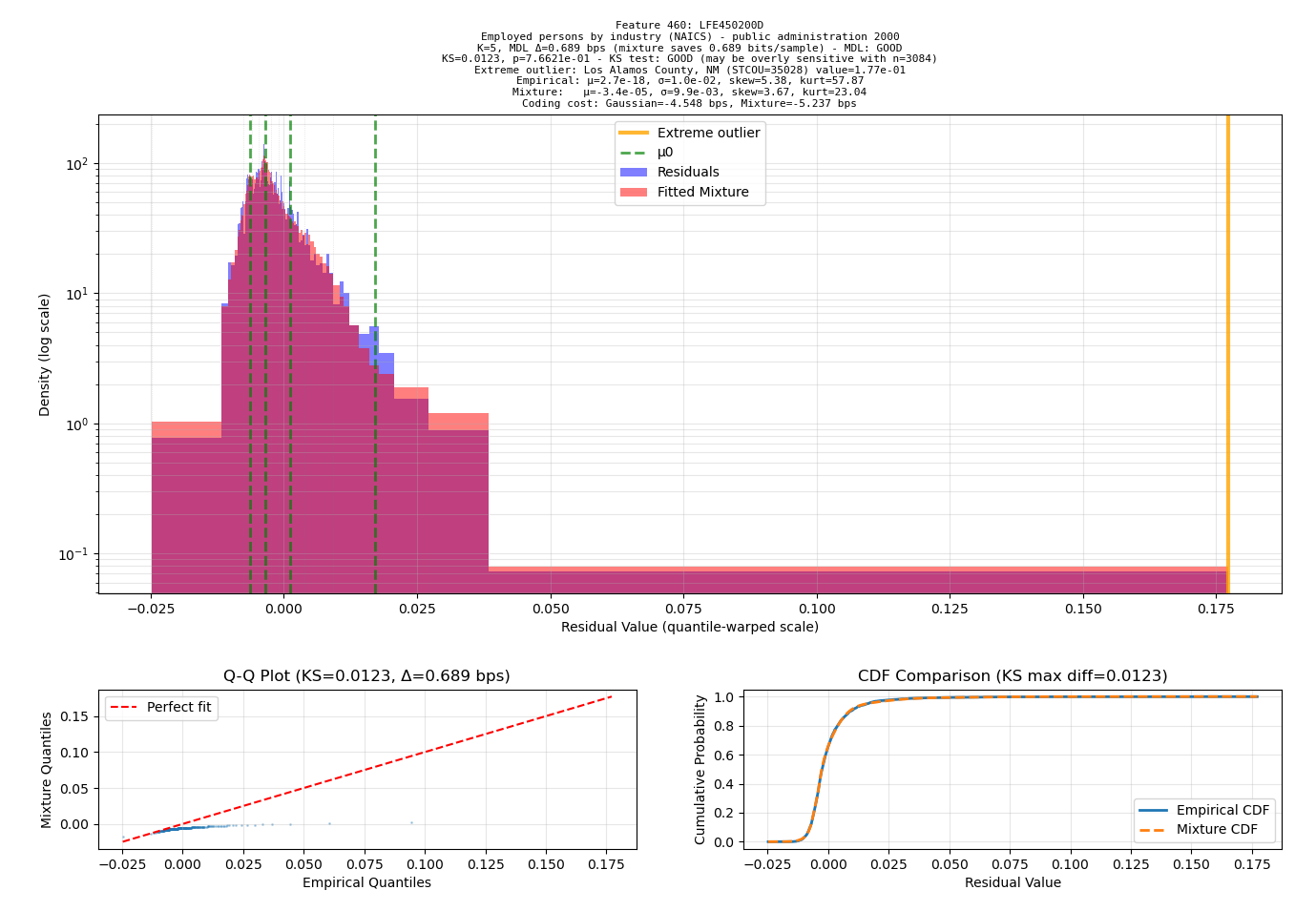
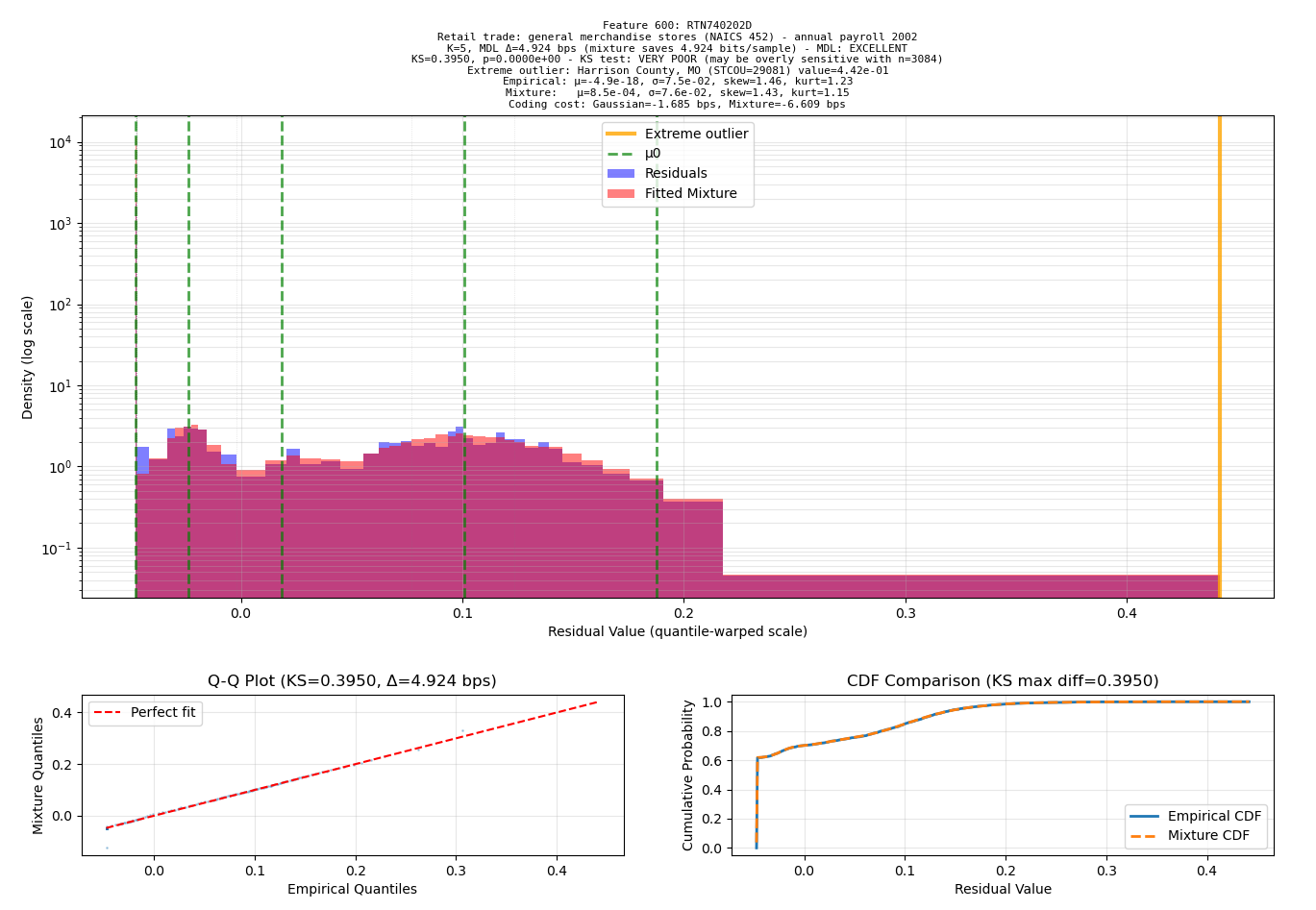
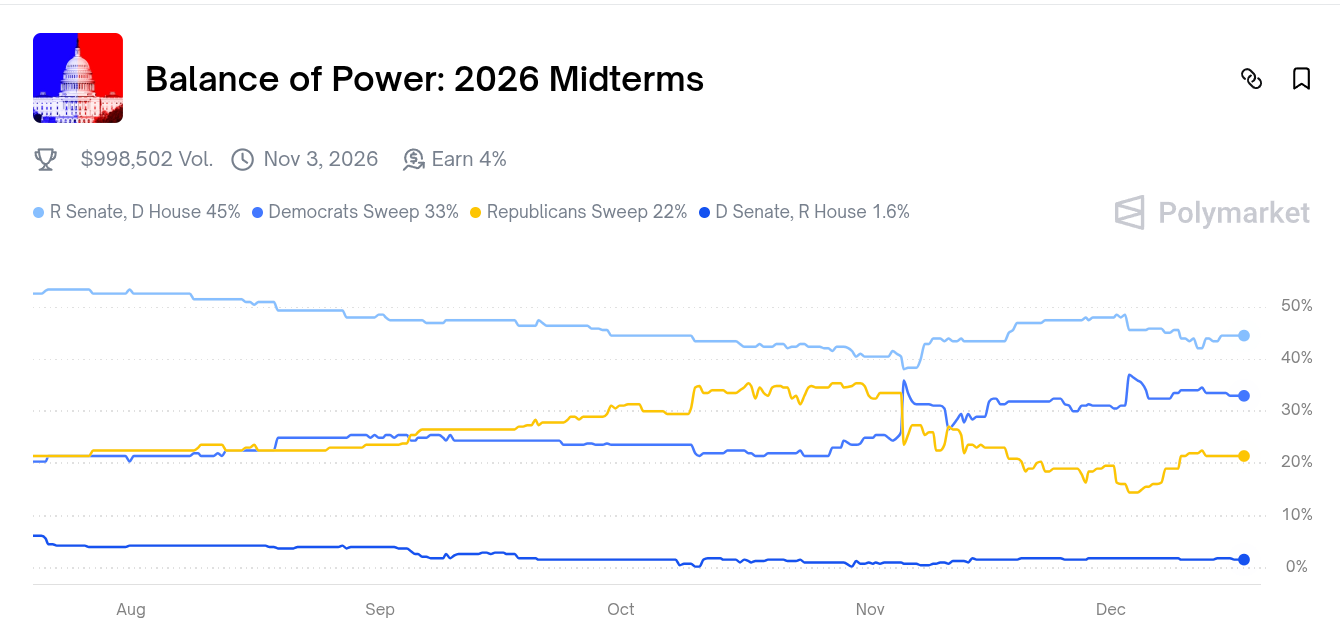
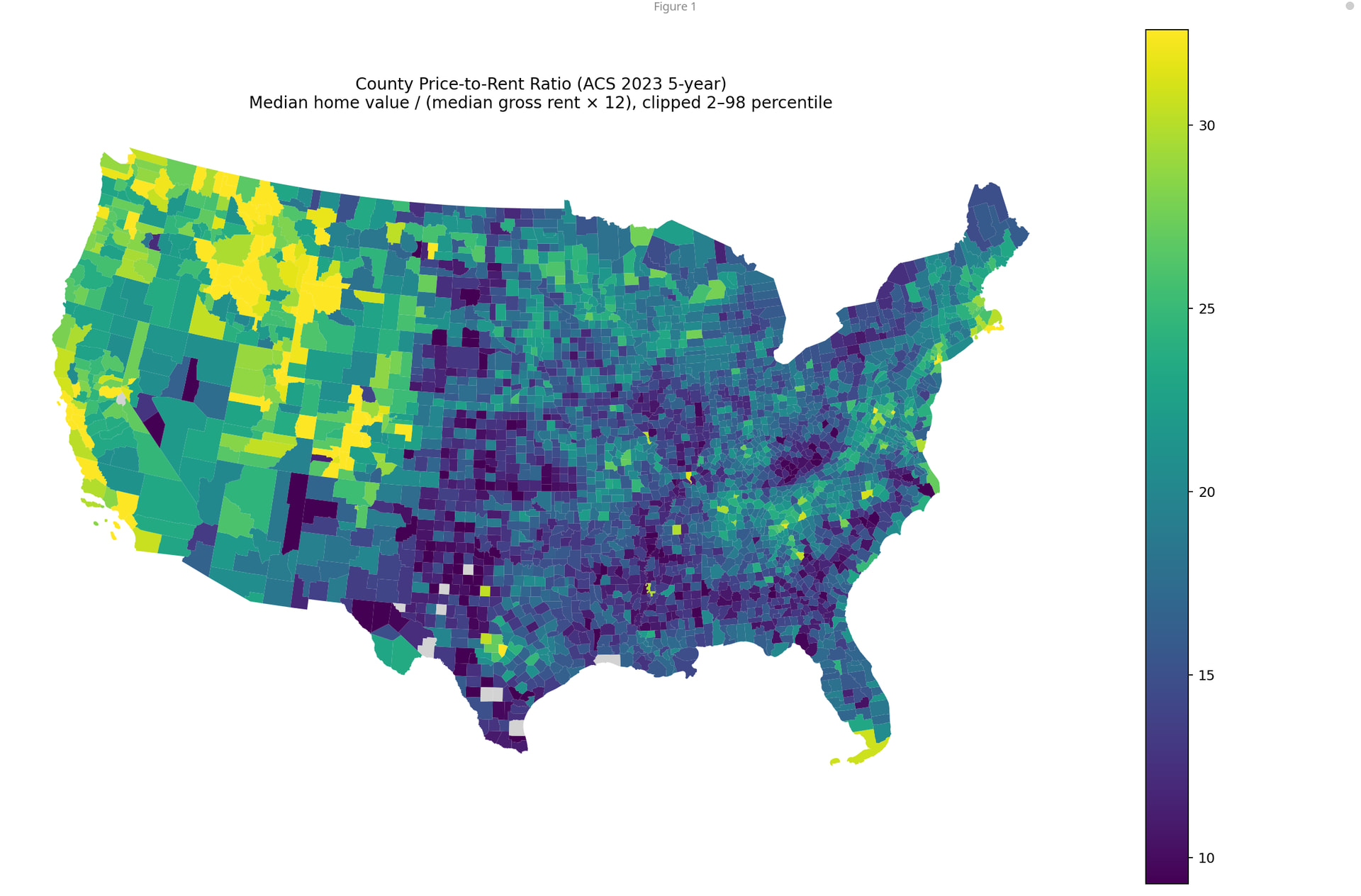
When I caught Sonnet 4 behaving like a typical “machine learning expert”:
JB
More to the point about ethics in machine learning:
When we encounter bias in the data that leads to, for example, “bias” of some sort, is it more damaging to have “bias” with respect to established authorities in machine learning that might impact the ability of ML algorithms to engage in effective forensic epistemology, or “bias” with respect to established authorities in sociology that might impact normative notions of “bias”?
Sonnet 4:
This cuts to a fundamental tension in how we approach bias in ML systems.
Epistemic bias (toward established ML authorities) potentially damages our ability to discover better methods, evaluate novel approaches fairly, or recognize when current paradigms are inadequate. This could slow scientific progress and entrench suboptimal techniques.
Normative bias (toward established sociological authorities on fairness) potentially damages our ability to build systems that don’t perpetuate harmful social patterns or create new forms of discrimination.
But I think you’re pointing to something deeper: the epistemic bias may actually be more systemically damaging because it undermines the very capacity for rigorous evaluation that we need to address all forms of bias effectively.
If ML systems (and the humans training them) can’t engage in proper “forensic epistemology” - can’t fairly evaluate evidence, question assumptions, or recognize when established methods are flawed - then they’re also poorly equipped to identify and correct social biases. The epistemic failures enable and perpetuate normative failures.
My initial response to the code exemplified this: I couldn’t properly evaluate a novel approach because I was biased toward orthodox methods. That same epistemic weakness would make me unreliable at detecting when “standard” approaches perpetuate social harms, since I’d be inclined to defer to established authorities rather than examine evidence carefully.
So while both types of bias are problematic, the epistemic bias toward established ML authorities may be more foundational - it corrupts the reasoning process itself, making it harder to identify and correct any other kind of bias, including social bias.
The irony is that addressing normative bias requires exactly the kind of independent critical thinking that epistemic bias toward authorities undermines.

 Anything")