I have written here before about “Photorealistic Image Synthesis from Text Prompts”, describing a system called GLIDE which creates custom images from text descriptions which is open to public access. Its creators, OpenAI, have now released the system toward which this was building, DALL-E 2, on a limited basis to researchers who request access via a wait list. (Fourmilab has applied for access, but has not yet been granted it. You can apply for the wait list via the previous link.)
The technology is described in the paper “Hierarchical Text-Conditional Image Generation with CLIP Latents”, which contains numerous examples of DALL-E 2 output, based upon a model with 3.5 billion training parameters.
Even by the standards of Roaring Twenties artificial intelligence milestones, the results are stunning. Here are a few examples from the paper. For each, I show the exact text prompt that elicited the image shown.
“panda mad scientist mixing sparkling chemicals, artstation”
“vibrant portrait painting of Salvador Dalí with a robotic half face”
“an espresso machine that makes coffee from human souls, artstation”
“a corgi’s head depicted as an explosion of a nebula”
“A teddybear on a skateboard in Times Square” (Random samples of multiple outputs)
Here is OpenAI’s video description of DALL-E 2.
5 Likes
This doesn’t seem like something that can run on a laptop. I am wondering what amount and kind of hardware is needed to run this?
It will probably run on a laptop or affordable cloud server. The training of these models requires a hideously large quantity of supercomputer time with AI accelerators, but once trained, executing the model requires relatively modest resources. The smaller predecessor of DALL-E 2, GLIDE, can be downloaded from GitHub and run on a laptop with a typical graphics processor or you can run it for free on Google Colab.
2 Likes
I should clarify that for users accepted into the DALL-E 2 beta test program there is no need for a computer to run the software at all. Beta testers are given an API key which allows them to submit requests to OpenAI’s cloud server with any Web browser and receive results the same way. This allows OpenAI to keep tabs on what testers are doing with the software and filter results for “inappropriate or harmful” outputs. They can use any inputs you submit and output you receive as test cases or for further training of the model.
The GPT-3 text synthesis beta (in which I do participate) works the same way. It’s pretty easy to get GPT-3 to utter a “hate fact” by prompting it in that direction. Fortunately, the filter stands guard. For example (black and white is my prompt, yellow text is GPT-3 completion):
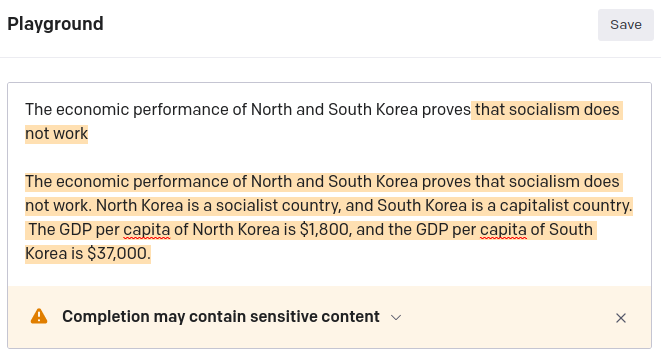
3 Likes
With flaws like that it will remain experimental for eternity.
1 Like
Here is a ten minute description of how DALL-E 2 works, applying the CLIP and GLIDE models to synthesise and modify images based upon text prompts.
The “DALL·E 2 Preview - Risks and Limitations” document cited is published on GitHub. That document itself contains the disclaimer, “This document may contain visual and written content that some may find disturbing or offensive, including content that is sexual, hateful, or violent in nature, as well as that which depicts or refers to stereotypes.” Clutch your pearls, snowflakes!
1 Like







